Onder de motorkap
Wat is er onder de motorkap allemaal verbeterd? ARM geeft duidelijk aan dat men bij de A78 meer overbodige functionaliteit heeft weggehaald dan dat er nieuwe zaken zijn toegevoegd. Geen wonder dat de core, zoals we op de vorige pagina hebben gezien, bij hetzelfde productieprocedé een paar procent kleiner is dan z’n voorloper. Verder zijn veel onderdelen van de het ontwerp geoptimaliseerd om met een lager energieverbruik te werken, zonder in te boeten op functionaliteit of prestaties. Desalniettemin is er ook zeker verbeterde functionaliteit te vinden.

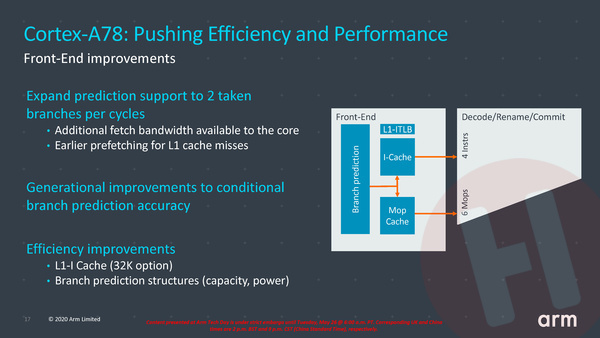
Om aan het begin van de pipeline te beginnen. Hoewel er weinig tot geen laaghangend fruit meer is in de front-end, is het verbeteren van de zogenaamde branch predictor voor cpu-ontwerpers één van de meest effectieve manieren om het stroomverbruik terug te brengen. Een snelle herhaling voor wie niet wekelijks in de materie van processor architecturen duikt: moderne cpu’s kunnen sneller werken door instructies niet in de volgorde zoals ze in software voorkomen uit te voeren, maar instructies zelf in een optimale volgorde te rangschikken, om zo alle verwerkingseenheden verderop in de processor zoveel mogelijk bezig te houden. Programma’s kennen echter vertakkingen (branches), bijvoorbeeld door als-dan-anders routines. Als de conditie voor zo’n vertakking nog niet verwerkt is, moet de processor gokken welke vertakking genomen gaat worden om alvast met die instructies verder te gaan. Is er goed gegokt dan gaat alles prima. Is er verkeerd gegokt, dan heeft de processor al vooruit gewerkt aan instructies die helemaal niet uitgevoerd hadden hoeven worden. Zonde van de energie én een reden voor vertraging omdat nieuwe, kloppende instructies helemaal van begin af aan door de pipeline geloodst moeten worden. Gelukkig hoeven processors niet letterlijk te gokken, want zogenaamde branch predictors worden steeds beter en kunnen met een steeds hogere succesratio de juiste vertakkingen inschatten. ARM heeft in de Cortex-A78 de branch preditor niet alleen weer een klein beetje accurater gemaakt, maar ook versneld doordat er nu twee vertakkingen per keer verwerkt kunnen worden.
Een andere verandering is dat er een optie is voor een kleinere L1 instructiecache; de sneller buffer tussen de grotere L2- en L3-caches en het begin van de pipeline. ARM heeft ingezien dat het verkleinen van deze cache geen noemenswaardig effect op de prestaties heeft, terwijl het wél weer transistors en energie scheelt.
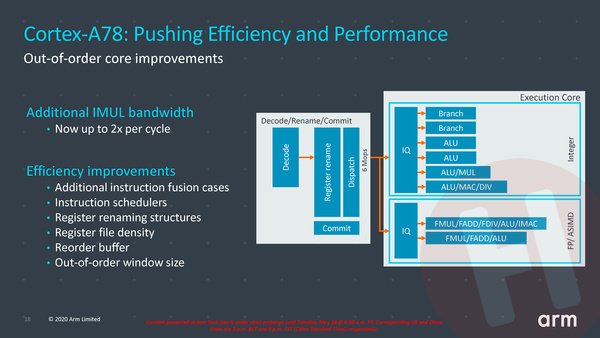
Bij de daadwerkelijk rekeneenheden, de execution units, vinden we voornamelijk efficiëntie voordelen. Er kunnen bijvoorbeeld vaker instructies gecombineerd uitgevoerd worden, het onderdeel dat zorgt voor de taakverdeling tussen de execution units (de schedulers) werkt efficiënter. Opvallend is dat ARM het aantal instructies dat tegelijkertijd in geoptimaliseerde volgorde op de radar kan blijven (het zogenaamde out-of-order window) iets heeft verkleind: ook hier gaf men aan dat het weinig tot geen effect had op de prestaties, maar wel op energieverbruik en transistors. Waar daadwerkelijk een verbetering zit is bij de execution unit die gehele getallen (integers) kan vermenigvuldigen: de bandbreedte daarvan is verdubbeld, aangezien dit in de praktijk een duidelijke bottleneck bleek.
Aan de caches heeft ARM ook gesleuteld. Zo zijn de prefetching algoritmes voor vrijwel alle cache-niveaus verbeterd. Zo’n prefetcher voorspelt welke data er op korte termijn nodig is en haalt deze data alvast op uit een verdere cache of uit RAM-geheugen. Hoe accurater de voorspellingen, hoe minder vaak er vertraging optreedt én hoe minder vaak onnodige data wordt opgehaald (wat uiteraard weer zonder van de energie is). Verder is de bandbreedte van de L2-cache verdubbeld én kunnen de execution units dubbel zo snel data uit de L1 data-cache halen. Beide zaken zorgen voor het weghalen van wat bottlenecks in het A77 ontwerp waar de A78 op is gebaseerd.

Cortex-X1 vs. A78
De Cortex-X1 kern is zoals geschreven gebaseerd op de A78. Alle optimalisaties die ARM in de A78 heeft doorgevoerd ten opzichte van de A77 zijn ook terug te vinden in de X1. Maar de X1 is een flink stuk groter, zoals we op de vorige pagina al lieten zien. Op heel veel plekken in de micro-architectuur biet de X1 grotere buffers, bredere datapaden en/of meer mogelijkheden om zaken parallel te doen.
Dat begint al in de front-end: waar de Cortex-A78 per klokslag 4 instructies uit de L1-instructiecache of 6 al eerder gedecodeerde micro-ops uit de micro-op-cache kan halen, zijn dat er bij de X1 respectievelijk 5 en 8. De micro-ops-cache, waarin het resultaat van de verwerking van de grotere instructies naar per instructie één of meerdere micro-ops wordt opgeslagen, is verdubbeld naar 3.000 posities. Dat maakt dat er minder vaak een identieke instructie opnieuw gedecodeerd hoeft te worden. En ook de buffer binnen de branch-preditor is vergroot.
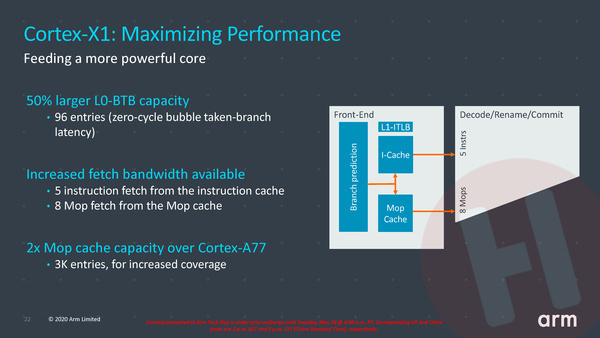
Vanuit de instructiedecoders kunnen er bij de Cortex-X1 8 instructies per klokslag naar de verwerkingseenheden worden gestuurd, tegenover 6 per klokslag bij de A78. Dat is niet zonder reden, want zoals we in de inleiding al schreven heeft de X1 ook simpelweg meer verwerkingseenheden. Voor is het aantal floating point execution units verdubbeld ten opzichte van de A78. En waar men bij de A78 het out-of-order window, ofwel het aantal instructies dat gelijktijdig op de radar kan blijven in de back-end van de processor, juist wat had verkleind, is het bij de X1 juist vergroot: van 160 bij de Cortex-A77 naar 224 bij de X1, 40% meer dus. Dat maakt dat de processor vaker instructies parallel kan uitvoeren, ook als die verder uit elkaar zitten in programmacode.
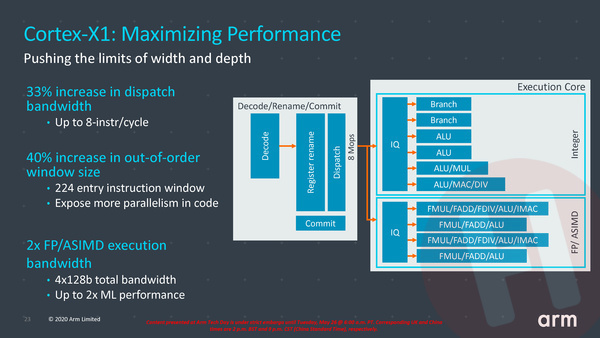
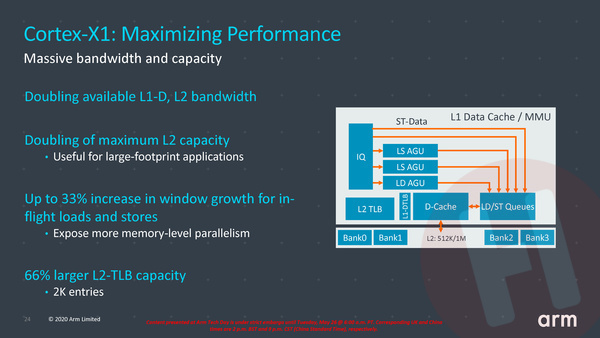
Bij de caches geldt dat alles groter en sneller is gemaakt en dat is dan ook direct de reden voor de flinke toename in transistors. We meldden al dat de maximale L2-cache capaciteit is verdubbeld naar 1 MB en de maximale L3-cache capaciteit is verdubbeld naar 8 MB. Tegelijkertijd is de bandbreedte van de L2-cache ook hier verdubbeld.