

Mali-G78: 2e generatie Valhall-architectuur
Vorig jaar was ARM’s grootste nieuws de Mali-G77 gpu, aangezien dit de eerste gpu was op basis van de nieuwe Valhall architectuur. De interne opbouw ging volledig op de schop, wat we in onze preview vorig jaar uitvoerig uit de doeken hebben gedaan. De G78 die ARM dit jaar introduceert is de 2e generatie Valhall gpu en daarmee een doorontwikkeling van het ontwerp van vorig jaar.
Zeker bij smartphones begint de gpu een steeds belangrijker onderdeel van de SoC te worden, aangezien meer en meer algoritmes efficiënter op de gpu dan op de cpu kunnen worden uitgevoerd. Denk vooral aan de vele zaken rondom machine learning en AI; of het nu gaat om slimme filters om foto’s of video te verbeteren, object herkenning, face unlock of augmented reality (het plaatsen van virtuele objecten in de echte omgeving), het zijn allemaal berekeningen die beter op de gpu dan de op de cpu werken.
Om maar weer even met de getallen te beginnen: in vergelijking met de Mali-G77 belooft ARM 25% betere prestaties. Verder is de de nieuwe gpu ook kleiner en zou ‘ie zo’n 10% efficiënter moeten werken. Specifiek voor machine-learning algortimes mag er een prestatiewinst van zo’n 15% verwacht worden.

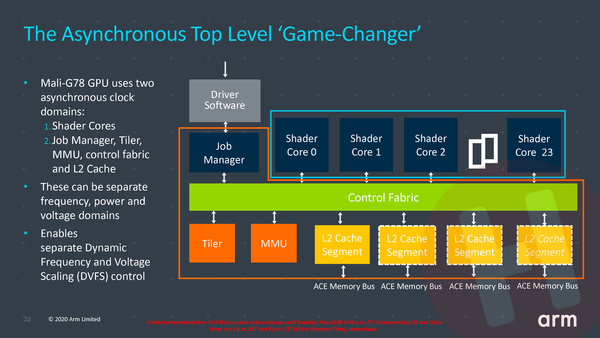
Er zijn twee belangrijke veranderingen die hieraan ten grondslag liggen. Allereerst heeft ARM de front-end van de gpu losgekoppeld van de shader cores, zodat beide delen van de gpu onafhankelijk van elkaar op andere klokfrequenties (en spanningen) kunnen werken. Daardoor kan de gpu in z’n geheel efficiënter werken, omdat juist het deel dat op een bepaald moment de bottleneck is versneld kan worden. Daarnaast zijn de blokken binnen de gpu-cores die de voor 3D- als ook ML-workloads belangrijke FMA-berekeningen (Fused Multiply Add, ofwel een gecombineerde vermenigvuldiging en optellen, nodig voor matrix-vermenigvuldigingen) uitvoeren, veel efficiënter kunnen geworden.

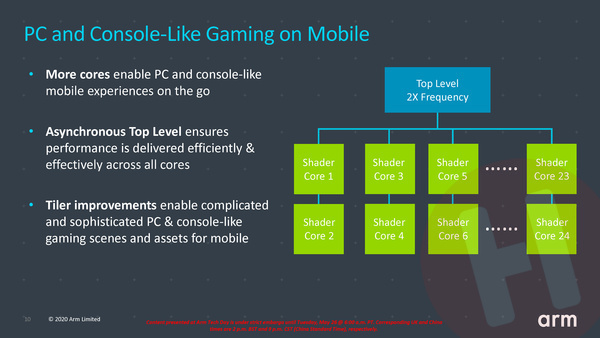
Om die eerste verbetering er maar even uit te lichten. Heel erg versimpeld kun je zeggen dat de front-end van de GPU (die ARM overige het top level noemt) zorgt voor de werkvoorbereiding en de shader cores voor het daadwerkelijk uitvoeren van berekeningen. In de praktijk kan het zijn dat het voorbereiden van het werk meer tijd in beslag neemt dan de daadwerkelijke berekeningen. De bottleneck ligt dan bij dat top level en door dat deel in klokfrequentie te verhogen wordt de gpu in z’n geheel sneller.
Het kan natuurlijk ook andersom: het kan ook zijn dat er in een bepaalde situatie in verhouding relatief weinig rekenkracht van de shader cores gevraagd wordt. Tot nu toe was de enige manier om dan stroom te besparen om een gedeelte van de shader cores uit te schakelen. Dat zorgt onderliggend echter altijd voor een flinke vertraging en is niet de optimale manier van stroom bespraken. Door de klokfrequentie van de shader cores en het top level los te trekken, kan de gpu nu de shader cores allemaal actief laten, maar terugschalen naar een veel lagere klokfrequentie en daarmee een veel lager stroomverbruik. Deze “low and slow” methode zorgt voor extra efficiëntie.
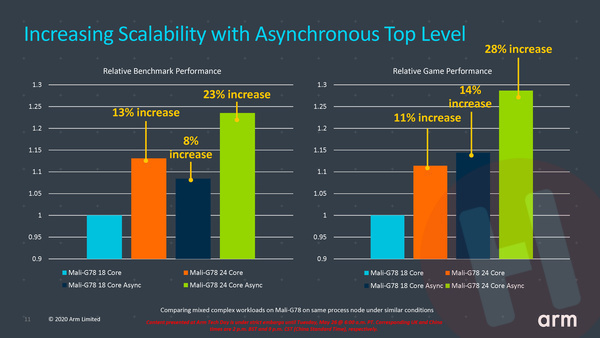
Wat levert dit nu op? Onderstaande slide moet dat aantonen. We zien in de grafieken het prestatie niveau van zowel een 18-core als een 24-core Mali-G78 variant en beide met asynchrone werking van top-level en shader cores in- en uitgeschakeld. De nieuwe methode kan de gpu zo’n 11% tot 15% sneller maken.
Onder de motorkap lijkt de Mali-G78 verder zoals geschreven veel op de G77. SoC fabrikanten hebben de mogelijkheid om 7 tot 24 G78-cores te combineren, een zelfde aantal als bij de G77. Naast de asynchrone top-level zijn er diverse (kleine) verbeteringen in de micro-architectuur, waaronder de genoemde nieuwe FMA-unit, een verbeterde tiler en verbeterde fragment dependency tracking.

De nieuwe FMA-unit is ontwikkeld met behulp van de collega’s die de Cortex cpu-cores ontwerpen. De architectuur van dit deel van de shader cores is geheel nieuw. Een belangrijke aanpassing is dat men aparte schakelingen heeft voor verwerking van 16-bit en 32-bit getallen: dat kost meer transistors, maar de flinke winst in efficiëntie is de investering waard aldus ARM. Omdat de FMA-units bij de Mali-G77 gemiddeld verantwoordelijk waren voor zo’n 19% van het totale energieverbruik van de gpu, is deze aanpassing erg belangrijk.
De meeste andere efficiëntiewinst komt uit een verbeterde tiler en slimmere informatiedeling. De Valhall-architectuur werkt, net als de meeste mobiele gpu’s overigens, via een tile based rendering principe. Dat betekent dat het volledig beeld wordt opgedeeld in meerdere vakjes (tiles) en dat het 3D-beeld per vakje wordt gerenderd. Aangezien zo’n vakje een relatief beperkt aantal pixels heeft, is de hoeveel data en de geheugenbandbreedte die nodig is voor het verwerken beperkt. Daarom werkt tile based rendering juist voor mobiele gpu’s, waar efficiëntie nog véél belangrijker is dan op de desktop, erg goed. Een uitdaging bij tile based rendering is echter dat objecten in de 3D-wereld geregeld gedeeltelijk op meerdere vlakjes zichtbaar zijn. De data voor de betreffende objecten moet dan voor meerdere tiles opgehaald worden. De Valhall-architectuur is nu geoptimaliseerd om dit véél beter dan voorheen te voorspellen. Wanneer er wordt gewerkt aan een tile en de gpu kan berekenen dat een object ook op de volgende te verwerken tile zichtbaar is, dan wordt de data voor dat betreffende object zodra de tile klaar is niet uit de cache geheugen verwijderd, maar juist bewaard. Dit kan volgens ARM tot 22% besparing van interne bandbreedte opleveren.

Last-but-not-least: ARM kondigt deze week niet alleen de Mali-G78 aan, maar ook de Mali-G68. Dit is een wat gekortwiekte variant van de GPU gericht op het wat ARM noemt sub-premium segment smartphones, de net-niet-topmodellen dus. Nu de topmodellen van fabrikanten steeds vaker richting, of zelfs boven de € 1000 kosten, wordt het segment dat daar onder zit van pak ‘m beet € 600 à € 800 steeds populairder. Het is een segment waar Qualcomm bijvoorbeeld de Snapdragon 765 voor introduceerde vorig jaar.
Het verschil tussen de G78 en G68 is simpel: waar de G78 geconfigureerd kan worden met tussen de 7 en 24 cores, is de G68 in feite exact dezelfde gpu, maar dan met maximaal zes cores. Hiermee doet ARM hier een trucje dat AMD en Nvidia bij desktops en laptops al jaren toepassen: minder uitgebreide varianten van dezelfde GPU een andere naam geven. Voor de consumenten is dat alleen maar goed en wat ons betreft mag ARM hier nog een stap verder in gaan. Voor de G78 geldt immers nog altijd dat deze in varianten van 7 tot 24 cores in een SoC kan zitten, wat in theorie een prestatiesverschil van meer dan een factor 3 kan betekenen. Net als nu bij de G77 zegt puur de naam “Mali-G78” in het lijstje specificaties van een SoC (of een smartphone) dus niks over de te verwachten prestaties wanneer het aantal cores niet duidelijk is.








