

De Cortex-A76 in detail
Microprocessoren maken gebruik van een pipeline, waarbinnen het uitvoeren van de instructies wordt opgedeeld in verschillende mini-stapjes, die achter elkaar worden uitgevoerd. Elke klokcyclus schuift elke instructie een stap door, totdat deze aan het eind van de pipeline is en dus volledig is uitgevoerd. De pipeline is bedacht om klokfrequenties hoger te krijgen: hoe kleiner en simpeler elke stap in de pipeline is, hoe minder tijd deze stap inneemt, en hoe hoger de klokfrequentie dus kan zijn.
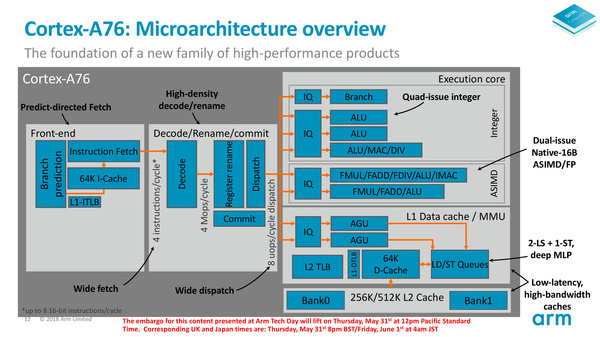
De pijplijn van de Cortex-A76 is net als veel vergelijkbare out-of-order processoren opgedeeld in drie zones. Er is de front-end, die instructies uit het geheugen ophaalt, de decode, de instructie decodeert en naar de goede plek stuurt, en de execution core, waar de instructie daadwerkelijk uitgevoerd wordt.
De pipeline: Front-end
Aan de front-end heeft Arm de grootste aanpassingen gedaan. De twee belangrijkste elementen in de front-end zijn de branch-predictor en de instruction-fetch. De eerste is verantwoordelijk voor het voorspellen welke instructie hierna uitgevoerd moet worden, terwijl de tweede de goede instructie met bijbehorende data dan uit het geheugen haalt en doorgeeft naar de decode-stage.
Waar bij eerdere Cortex-ontwerpen deze twee nog geïntegreerd waren, zijn ze in de A76 losgetrokken. Dit is gedaan om de branch-predictor te vergroten: deze kan nu acht 32-bits instructies tegelijkertijd ophalen in plaats van vier. Deze worden vervolgens in de instructie-cache geplaatst, totdat de fetch-eenheid de bijbehorende data daarbij heeft gevonden.
De fetch kan echter nog steeds maar vier instructies plus data doorgeven per klokcyclus. De kans is nu aanwezig dat je je afvraagt waarom de branch-predictor een twee maal zo hoge doorvoercapaciteit heeft gekregen als de instruction-fetch; het antwoord is tweeledig.
Ten eerste kan er een cache-miss plaatsvinden. Dit gebeurd als branch-predictor niet op tijd heeft gezien dat een bepaalde instructie uitgevoerd moet gaan worden, en dus niet de benodigde data uit hogere cache-lagen of zelfs het werkgeheugen heeft opgehaald. Op dat moment vindt een cache-miss plaats en kan de instructie niet uitgevoerd worden totdat de benodigde data is aangevoerd, wat zo tientallen klokcycli kan duren. Het tweede wat een fetch kan overkomen is dat er toch een ander pad in de code is genomen dan voorspeld. Een if-statement kan toch niet waar zijn, een while-loop kan ineens ophouden of een andere klasse kan plotseling aangeroepen worden. In dat geval kunnen alle instructies die in dat pad voorspeld werden, worden weggegooid.
In beide gevallen komt een in-order kern dan volledig stil te liggen, maar een out-of-order variant kan gelukkig ook andere instructies voor laten gaan. Dat is waar die bredere branch-predictor in de Cortex-A76 komt kijken: als de fetch-eenheid nog niet de data heeft of instructies moet weggooien, dan moeten er wel andere instructies klaar staan om uit te voeren. Daarvoor is tussen de branch-predictor en de fetch een instructie-cache van 64kB aanwezig, waar een paar duizend instructies in kunnen worden opgeslagen.
Door de branch-predictor te vergroten en de buffers in de front-end te vergroten, heeft Arm vele bottlenecks kunnen oplossen en zorgt het ervoor dat de andere onderdelen van de cpu veel minder vaak droog komen te staan, met betere prestaties tot gevolg.
De pipeline: Decode
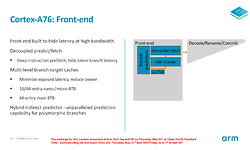
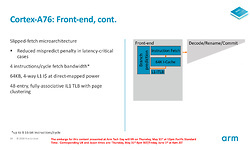
Wanneer de instructies dan succesvol zijn doorgegeven door de fetch-eenheid, dan mag de decoder aan de slag. Deze grote instructies kunnen namelijk niet direct door de executie-eenheden uitgevoerd worden, maar moeten eerst vertaald worden in macro- en daarna zelfs micro-operaties. De decoder kan net als de fetch 4 instructies per klokcyclus aan die vertaald worden in macro-operaties. Daarvan kunnen er vier doorgegeven worden.
Gemiddeld vertaalt een instructie zich echter in 1,06 macro-operatie (een klein aantal instructies neemt twee macro-operaties in), waardoor er soms dus nog wel een kleine bottleneck zit in de decoder. Ook kon de decoder in de Cortex-A73 en -A75 integer-instructies in slechts een klokcyclus doorgeven, terwijl het nu voor alle instructies twee klokcyclus de tijd neemt.
De macro-operaties worden in een register geplaatst, waar de dispatch ze oppakt en doorstuurt naar de execution-engine. Hierbij worden ze echter nog vertaald naar micro-operaties. Omdat een macro-operaties zich gemiddeld vertaalt in 1,2 micro-operaties, is gekozen de dispatch 8-wide te maken, waardoor er bijna nooit een bottleneck ontstaat. De dispatch van de Cortex-A73 was slechts 4-wide, terwijl de A75 een dispatch van 6-wide had. Tevens is het Arm gelukt om het aantal klokcycli dat de dispatch nodig heeft terug te dringen van 2 naar 1.

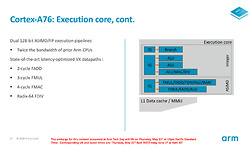
De pipeline: Execution core
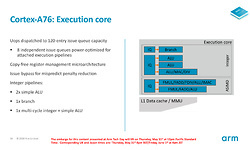
In de execution-core worden de instructies en de bijbehorende data dan eindelijk uitgevoerd. De instructies zijn via de dispatch in verschillende issue-queues geplaatst, waarna ze uitgevoerd worden door de verschillende executie-eenheden. Die issue-queues kunnen bij de A76 elk 120 instructies bevatten, dus zelfs wanneer in het geval van een branch miss er meerdere instructies teruggetrokken moeten worden, is de kans groot dat er nog voldoende uit te voeren instructies over blijven, waardoor de execution engines zelden tot nooit stilstaan.
Voor integer-operaties zijn er twee simpele ALU's, waar alleen optellen, aftrekken en het verschuiven van bits binnen een getal mogelijk is. De derde is een zogenaamde multi-cycle eenheid, die door middel van herhaaldelijk optellen en aftellen ook kan vermenigvuldigen. Delen gebeurt dan weer door meerdere van deze multi-cycle operaties. Verder zijn er twee 128-bit floating-point execution units, waarvan Arm de bandbreedte ten opzichte van de vorige generatie heeft verdubbeld. Geen wonder ook dat juist bij floating point berekeningen het prestatieverschil tussen A76 en A75 het grootste is.
Caches: meer en sneller
Ook bij de caches zijn er flinke verbeteringen doorgevoerd, niet in de laatste plaats om de Cortex-A76 beter geschikt te maken voor typische laptop workloads. Sterker nog, Arm geeft aan dat misschien wel het grootste deel van de prestatiewinsten te danken is aan de cacheverbeteringen.
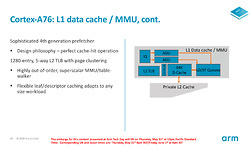
Voor de L1-cache, die het dichtst op de cpu-cores zit, heeft Arm de verwerking voor het generen van geheugenadressen en voor het ophalen van data uit diepere caches losgetrokken, om zo de bandbreedte te optimaliseren. Net als bij de Cortex A75 bestaat de L1-cache uit 64 kB voor instructies en 64 kB voor data. De latencies hiervan zijn echter verbeterd; bovenal bevat de L1-cache binnen de A76 een verbeterde prefetcher, die beter voorspelt welke data uit de L2-cache binnenkort nodig is en die ook sneller ophaalt, wat het percentage cache-hits voor de L1 moet verbeteren. De L2-cache is afhankelijk van de implementatie 256 kB of 512 kB per core, waarbij opnieuw de bandbreedte is vergroot. Verschillende cores kunnen ten slotte nog een groot stuk L3-cache delen. Was die bij A75 nog beperkt tot maximaal 2 MB, is die bovengrens nu verhoogd tot 4 MB. Zeker bij laptop workloads, die relatief veel toegang tot het geheugen nodig hebben, kan de grotere L3-cache voor een aanzienlijke prestatiewinst zorgen.
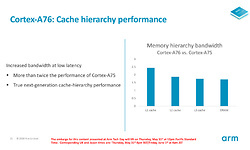
Arm geeft aan dat de bandbreedte van de L1-cache tot 2,5x hoger is ten opzichte van de Cortex-A75. De bandbreedte voor de L2- en L3-caches is zo'n 1,5x à 2x hoger. Alles bij elkaar opgeteld moet data veel sneller door de cpu geloodst kunnen worden dan voorheen.


Wat levert dit alles nu op?
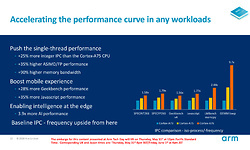
We schreven al dat een Cortex-A76 met hogere klokfrequentie en een state-of-the-art productieprocedé ruim 35% sneller kan zijn dan zijn voorloper. Met identieke klokfrequentie en identiek productprocedé belooft Arm een stijging van de IPC (het gemiddelde aantal instructies dat per klokslag wordt afgerond) van 25%. Dat zijn waardes waar we in de x86-wereld de laatste jaren alleen maar van kunnen dromen. De floating point prestaties zouden zelfs 35% hoger moeten liggen en dankzij de verschillende verbeterde caches de gemiddelde geheugenbandbreedte zelfs 90%.
Hoe te gebruiken
Zoals geschreven brengt Arm dit jaar enkel een nieuwe "grote" cpu-core op de markt. De Cortex-A76 kan zodoende net als voorloper Cortex-A75 gecombineerd worden met de bestaande, "kleine" Cortex-A55 kernen, binnen DynamIQ configuraties. Daar staat helemaal vrij welke keuzes gemaakt worden, waarbij Arm verwacht dat 1+7, 2+6 en 4+4 vermoedelijk het meest gebruikt zullen worden.
Wie snel kan rekenen zie dat dit allemaal 8-core combinaties zijn. Wat is er mis met 2+2 of 2+4? Helemaal niets; sterker nog, 2+4 is volgens Arm voor veel smartphones vermoedelijk zelfs de beste configuratie. Het feit dat smartphonefabrikanten niet voor hun concurrenten onder willen doen en dus willen kunnen roepen dat ze een 8-core processor hebben, én het feit dat het getal 8 in China het geluksgetal is, maakt dat 8-core configuraties volgens Arm in 2019 het meest populair zullen zijn. Gelukkig zijn A55-kernen dusdanig klein dat het op de totale productiekosten van de chip vrijwel niets uitmaakt of er nu vier of zes kleine kernen zijn geïmplementeerd...








