

Zen 2 in detail
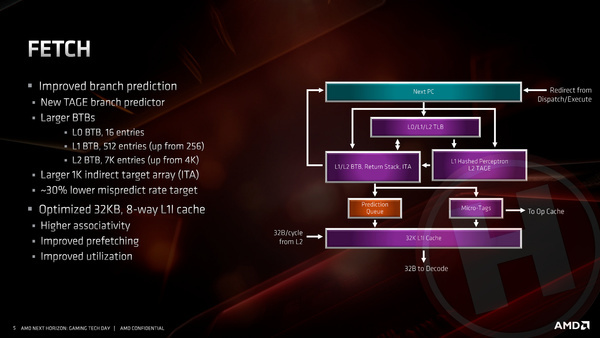
In de front-end van de processor is de belangrijkste vernieuwing de implementatie van een nieuwe branch-predictor, die volgens het TAGE-principe werkt. Het uiteenzetten van de precieze eigenschappen van een dergelijke branch predictor gaat wat ver voor dit artikel, maar uit wetenschappelijke studies blijkt dat een dergelijke voorspeller de beste resultaten biedt. Het daadwerkelijk implementeren van een TAGE branch predictor is volgens AMD’s hoofd CPU-ontwerpen Mike Clark echter allesbehalve triviaal.
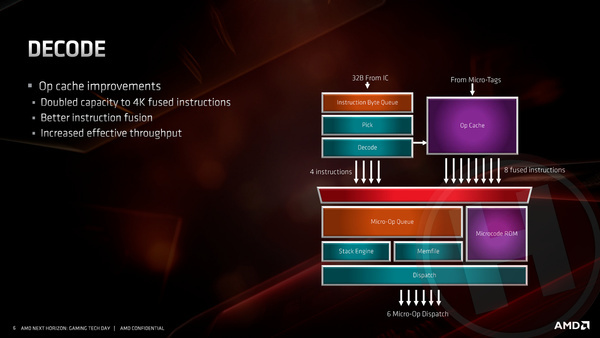
Een andere belangrijke aanpassing is het verdubbelen van de grootte van de micro-op cache naar 4000 instructies. X86 processors worden aangestuurd met duizenden zeer grote instructies, die te complex zijn om in een keer door de processor verwerkt te worden. Vandaar dat die complexe X86-instructies worden gedecodeerd naar micro-op’s, kleinere instructies die de execution units wel kunnen verwerken. Dit decoderen kost uiteraard ook tijd en energie. Door het resultaat van gedecodeerde instructies op te slaan in speciaal cachegeheugen, hoeft het decoderingsproces niet opnieuw plaats te vinden wanneer eenzelfde instructie na korte tijd opnieuw wordt aangeleverd. Hoe groter deze micro-op cache, hoe vaker de decodering kan worden overgeslagen, hoe hoger de prestatiewinst én de winst qua energieverbruik.
Verder heeft AMD in de front-end het bij elkaar voegen van micro-ops tot setjes die gezamenlijk richting de execution units worden gestuurd verbeterd, ook dit met als doel om zo vaak mogelijk zo veel mogelijk execution units tegelijkertijd nuttig werk te laten doen. Het vergroten van de op cache kost natuurlijk de nodige transistors; om dit fysiek mogelijk te maken heeft AMD de L1 instructiecache verkleind van 64 kB naar 32 kB. De instructiecache bevat de x86-instructies die zijn opgehaald uit het geheugen om verwerkt te gaan worden. Door deze cache echter meer in- en uitgangen te geven (8-way associative in plaats van 4-way associative), door de algoritmes voor het zo slim mogelijk vooraf ophalen van instructies (pre-fetching) te verbeteren én door de vergroting van de caches op andere niveaus (specifiek de L3-cache), is het effect van de kleinere instructiecache volgens AMD zeer beperkt.
Vanuit de front-end kunnen per klokslag zes micro-op’s richting de execution units gestuurd worden.
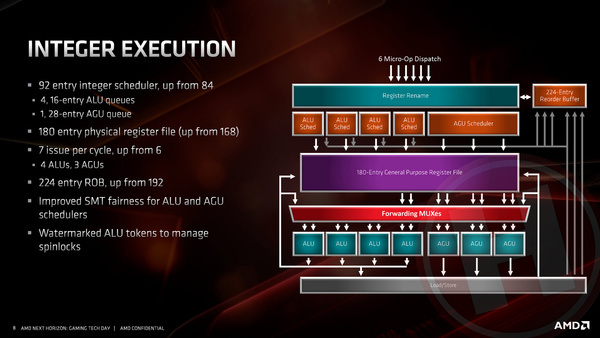
In de back-end van de processor heeft AMD bij de integer (gehele getallen) execution units een aantal veranderingen doorgevoerd. Allereerst is er een derde address generation unit, een rekeneenheid die geheugenadressen kan berekenen, toegevoegd. Het maakt dat het totaal aantal integer rekeneenheden is verhoogd van zes naar zeven. Om alles in evenwicht te houden is het aantal instructies dat klaargezet kan worden om verwerkt te worden verhoogd van 84 naar 92.
Verder is de re-order buffer verhoogd van 192 naar 224 instructies. Zoals we al schreven optimaliseren moderne processors de volgorde van binnenkomende instructies om deze sneller en efficiënter uit te kunnen voeren. Om maar bij de analogie van de vorige pagina te blijven: door deze buffer te vergroten, kan Zen 2 in de spreekwoordelijke Ikea-catalogus de stappen van 224 pagina’s in plaats van 192 pagina’s vooruit lezen en in slimmere volgorde doen.
Binnen de integer unit zijn ook verbeteringen doorgevoerd voor de werking van simultaneous multi-threading, ofwel het door één CPU-core laten uitvoeren van instructies voor twee programma-threads. De CPU herkent nu automatisch wanneer een thread tijdelijk dummy-instructies aan het uitvoeren is omdat er gewacht wordt op data (een zogenaamde spinlock), en geeft dan automatisch de andere thread meer prioriteit. Het maakt dat sporadische nadelen van SMT nog sporadischer worden.
De grootste verandering zit hem vermoedelijk bij de floating point execution units, de rekeneenheden die met gebroken getallen kunnen rekenen. Bij de Zen-architectuur zijn deze geschikt voor 128-bit getallen: wanneer er berekeningen gedaan moesten worden met 256-bit getallen middels AVX2-instructies, moest dat altijd in meerdere stappen gebeuren.
Bij Zen 2 zijn de floating point units en alle periferie volledig geüpgraded naar 256-bit. Hierdoor kunnen AVX2-instructies nu, net als bij moderne Intel processors, in één klokslag verwerkt worden. Bij programma’s die gebruik maken van AVX2-instructies kan de prestatiewinst ten opzichte van de vorige generatie Ryzen-processors dus nog verder oplopen.
Overigens biedt Zen 2 nog geen ondersteuning voor AVX512. Bij navraag gaf AMD te kennen dat het voor de hand zou liggen om 512-bit instructies op een vergelijkbare manier aan te pakken als 256-bit instructies bij eerste generatie Zen, maar dat binnen Zen 2 simpelweg nog geen ondersteuning is ingebakken voor de specifieke nieuwe instructies van AVX512. Tussen neus en lippen door begrepen we echter dat AVX512 zo maar eens bij Zen 3 toegevoegd zou kunnen worden.
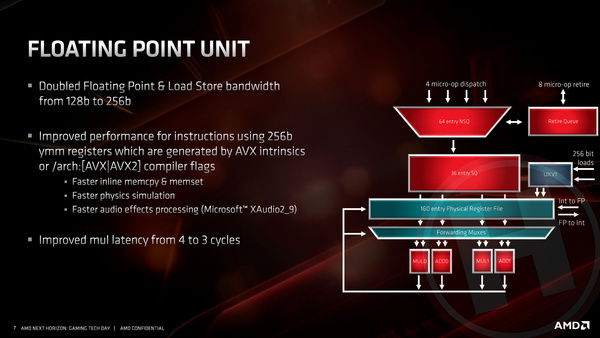
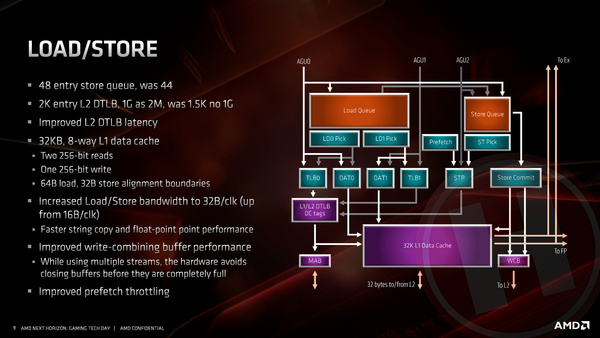
Bij de load/store-units, die data van en naar de caches en via die weg van en naar het geheugen transporteren, zijn er ook de nodige verbeteringen doorgevoerd. Daarvan is een verdubbeling van de bandbreedte van 16 bytes per klokslag naar 32 bytes per klokslag de belangrijkste. Deze aanpassing is onder andere nodig om de nieuwe 256-bit floating points snel genoeg data te laten wegschrijven of ophalen. Verder zijn binnen de load/store-unit de nodige buffers vergroot of versneld.
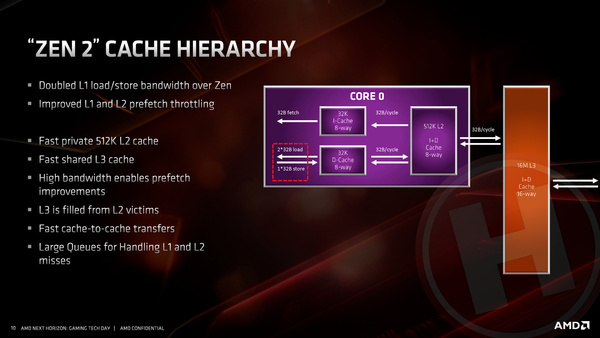
We schreven al dat de L1 instructiecache is gehalveerd van 64 kB naar 32 kB. De L1 datacache was 32 kB bij Zen en is dat bij Zen 2 gebleven. Ook ongewijzigd is de L2 cache, die nog steeds 512 kB per core bedraagt. De door de cores gedeelde L3-cache is echter verdubbeld. Net als bij de eerste generatie Zen zitten vier cores bij elkaar in een groepje genaamd een core-complex (CCX). Had zo’n CCX bij eerdere Zen-processors 8 MB L3-cache, is dat bij Zen 2 verdubbeld naar 16 MB L3-cache. De belangrijkste reden voor de verdubbeling is dat de latencies voor het aanspreken van werkgeheugen iets zijn toegenomen door de opbouw met chiplets, waarbij de geheugencontroller fysiek in een andere chip zit.
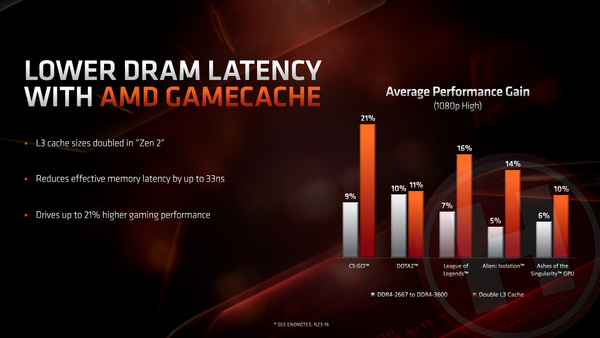
De grotere L3-cache zorgt er uiteraard voor dat Ryzen-processors minder vaak naar ram-geheugen hoeven te gaan om data op te halen of weg te schrijven. Het kan in veel gevallen, en zeker bij games, voor meer dan 10% prestatiewinst zorgen, aldus AMD.
Terug naar de twee pagina’s terug beschreven chiplets. De cpu-chiplets (CCD ofwel core complex die in jargon) bevatten zoals geschreven elk acht cores en dus twee CCX’en van elk vier cores. Ze communiceren middels AMD’s Inifinity Fabric-technologie met de I/O-die. Die Infinity Fabric communicatie biedt een snelheid van 32 bytes per klokslag. In de I/O-die (om het juiste jargon te gebruiken: coherent I/O die ofwel cIOD) zitten vervolgens onder meer de geheugen- en pci-express controllers.

We schreven al dat AMD zich vroeg in de ontwerpfase van Zen zorgen maakte over de maximale klokfrequentie die mogelijk zou zijn met het 7nm-procedé. Die zorgen bleken onterecht. Waar het bij de eerste generatie Ryzen (14nm) een maximale klokfrequentie van 4,1 GHz kon behalen en bij de tweede generatie Ryzen (12nm) een maximale klokfrequentie van 4,35 GHz, gaat er bij de 3e generatie Ryzen nog eens 250 MHz bovenop: 4,6 GHz dus. En een klein aantal van de chips gaat zelfs nog iets verder, waardoor de 16-core Ryzen 9 3950X een officiële turbofrequentie van 4,8 GHz kan krijgen.

Waar we ten slotte nog even bij stil moeten staan: de Zen 2-architectuur biedt hardwarematige beveiliging voor de Spectre en Spectre v4 beveiligingsproblemen, waar AMD eerder al firmware/software-remedies voor uitbracht. Voor andere beveiligingsproblemen als Meltdown, Foreshadow en MDS zijn de AMD-processors nooit vatbaar geweest.

Overigens: tijdens de presentatie van de nieuwe Ryzen-processors gaf AMD’s CTO Mark Papermaster te kennen dat de 3e generatie Zen-architectuur keurig op schema ligt. Deze zal in 2020 of 2021 geïntroduceerd worden op een geoptimaliseerd 7nm-procedé.

5 besproken producten
| Vergelijk | Product | Prijs | |
|---|---|---|---|

|
AMD Ryzen 5 3600 Boxed
|
€ 85,1010 winkels |
|

|
AMD Ryzen 5 3600X Boxed
|
€ 199,002 winkels |
|

|
AMD Ryzen 7 3700X Boxed
|
€ 318,182 winkels |
|

|
AMD Ryzen 7 3800X Boxed
|
€ 290,431 winkel |
|

|
AMD Ryzen 9 3900X Boxed
|
€ 463,531 winkel |







