

Nvidia heeft in maart de Hopper-architectuur gelanceerd, in de vorm van de H100-accelerator voor datacentra. Nu heeft de fabrikant een whitepaper van 71 kantjes gepubliceerd waarin de te verwachten prestaties en de opbouw van de gigantische monolithische gpu in detail uitgelegd wordt. Er zijn twee uitvoeringen, als insteekkaart en als servermodule die beide gebruik maken van de GH100-gpu van ruim 800mm2. Beide beschikken over 80GB geheugen, 50MB L2-cache, pcie 5.0 en de vierde generatie NVLink.

De pcie-versie heeft 114 van de 144 van de streaming multiprocessors ingeschakeld, voor 14.592 cuda cores en 456 Tensor-cores. Met vijf hbm2e-stacks worden 10 van de 12 controllers met een busbreedte van 512 bits elk gebruikt. Het tdp is 350 watt, een specificatie de de sxm5-module verdubbelt. Die heeft 132 sm's ingeschakeld voor 16.896 cuda cores en 528 Tensor-cores, daarnaast worden er 5 stacks hbm3 gebruikt. Als de prestaties niet per uitvoering gespecificeerd zijn wordt verwezen naar de sxm5-versie, die dankzij het hogere aantal cores en het verdubbelde tdp flink sneller kan zijn.

FP32-prestaties gaan maal drie
Op het gebied van de productie heeft Nvidia flinke stappen kunnen zetten dankzij TSMC's N4-proces. De transistordichtheid is 50 procent hoger vergeleken met Ampère. Daardoor kon het aantal fp32-shaders op elke streaming multiprocessor verdubbeld worden. Samen met een beloofde verbetering in kloksnelheid zouden de prestaties drie keer zo hoog uit moeten pakken als die van de voorgaande generatie.
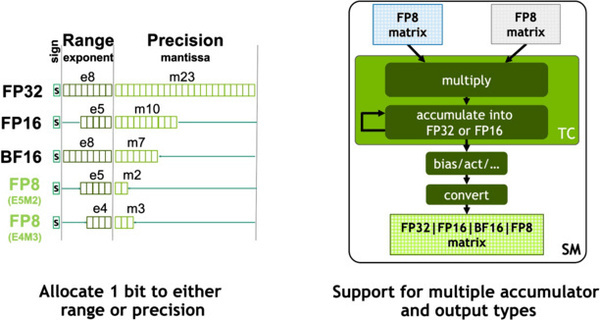
Het fp8-getalsformaat is nog zo nieuw dat de standaard implementatie van de IEEE rechtstreeks overgenomen is. Hiermee wordt het formaat nu twee keer zo snel berekend als toen het nog als fp16 verwerkt werdt. Er kan gekozen worden voor twee formaten voor floating point-berekeningen. E4M3 biedt een grotere nauwkeurigheid, waar E5M2 een groter aantal getallen mogelijk maakt. Het getal voor het resultaat van de matrix-operatie kan zelfs in vier formaten gegeven worden.
Wie sterk is kan ook slim zijn
Nvidia wil de rekenkracht van Hopper zo efficiënt mogelijk inzetten. Daarom zijn instructies voor dynamisch programmeren toegevoegd. Bij vraagstukken waarbij vooraf berekende uitkomsten telkens opnieuw worden gebruikt kunnen deze effectiever behouden worden. Bij bijvoorbeeld optimalisatieproblemen kan het oplossen in het beste geval met een factor 7 versneld worden door herhaaldelijke berekeningen overbodig te maken.

Waar een sm met 128 shaders voorheen de eenheid was waarop taken verdeeld werden is dit nu uitgebreid. Meerdere sm's kunnen in een cluster samen ingezet worden en toegang krijgen tot de cache van de andere processors. Dit moet veel sneller zijn dan het opnieuw inladen van gegevens. Voor sommige applicaties kan dit een verdubbeling in prestaties opleveren.
Snellere Tensorkernen voor matrices
Tensorkernen worden voor een specificieke rekentaak gebruikt. Bij het vermenigvuldigen van twee matrices moet een derde matrix berekend worden voor het resultaat, en dat is het enige waarvoor deze kernen gebruikt kunnen worden. De toepassing van matrices in het trainen van neurale netwerken is zo belangrijk dat deze een eigen set rekenkernen heeft gekregen.
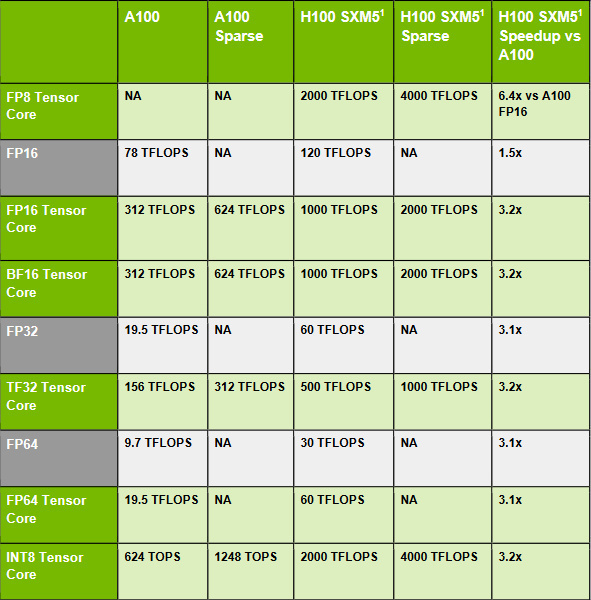
De vierde generatie Tensor-cores verdubbelt de prestaties per clock voor alle ondersteunde getalsformaten. Aangezien kp8 voorheen als kp16 verwerkt werd wordt daar zelfs een factor 4 behaald. De prestaties nemen nog eens 50 procent toe door een hoger aantal kernen met een hogere klokfrequentie. Voor het overbrengen van de matrices naar de Tensor-cores komt snel geheugen goed van pas. De Tensor Memory Accelerator is nu verantwoordelijk voor deze gegevensoverdracht om de sm te ontlasten, wat resulteert in hogere prestaties.
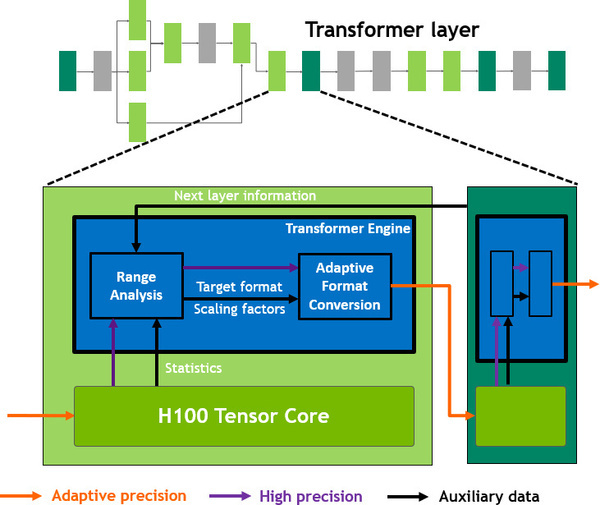
De nieuwe Transformer-engine maakt gebruik van een algoritme voor het trainen van een ai voor spraakherkenning. Door de nauwkeurigheid bij elke stap aan te passen tussen fp8 en fp16 kan prestatiewinst behaald worden. Daarvoor wordt het voorgaande resultaat gebruikt om de vereiste precisie bij de volgende berekening te voorspellen. Er wordt daarbij rekening gehouden met de lagere nauwkeurigheid en kleinere getalsruimte van fp8 en het gewenste eindresultaat.
Videodecoders, maar niet voor beeld
De videodecoders die ingebouwd zijn in deze server-gpu worden niet gebruikt om een beelduitvoer te genereren. Het videomateriaal voor het trainen van deep learning-modellen meot gedecodeerd worden. Het aantal gelijktijdige streams dat verwerkt kan worden is verdubbeld tot 340 full hd-streams. Er is ondersteuning voor H.265, H.264 en VP9. Daarnaast kunnen tot 6.350 full hd-beelden per seconde gecomprimeerd worden tot een jpeg-bestand.
Focus op AI
Uit al deze getallen blijkt dat Nvidia met deze generatie zoveel mogelijk ai-prestaties in een gigantische chip heeft gestopt. Op het gebied van de klassieke vectorberekeningen blijft AMD met de MI200 en CDNA2 het groene kamp soms nog net voor. Opvallend genoeg gebruik de concurrent al chiplets of tiles. Vooralsnog heeft Nvidia deze aanpak nog niet gebruikt, daar liggen mogelijk dus nog prestaties die in de toekomst aangeboord kunnen worden.
Bron: ComputerBase

