AVX2
AVX2 is een uitbreiding op de AVX-instructieset, die bij Sandy Bridge werd geïntroduceerd. Om het geheugen even op te frissen: het belangrijkste onderdeel van AVX was dat Intel de floating point rekeneenheden van de processor had opgewaardeerd om te kunnen werken met 256-bit getallen. Daarnaast bevatte AVX een twaalftal nieuwe instructies, waarvan een aantal geschikt voor drie variabelen, waarvan een instructie om C = A + B te doen het belangrijkste voorbeeld is. Om hetzelfde te bewerkstelligen moeten processors zonder AVX-instructies wegens een maximum van twee variabelen minimaal twee instructies uitvoeren: eerst A = A + B en daarna C = A.
AVX2 borduurt verder op de ideeën van AVX. Een belangrijke vernieuwing is dat bij Haswell ook de integer rekeneenheden met 256-bit getallen kunnen werken. Daarnaast wordt het aantal instructies dat geschikt is om te werken met drie variabelen verder uitgebreid, met onder meer instructies voor vermenigvuldigen en bit operaties. Verder komen er nieuwe instructies om data volgens het zogenaamde gather-scatter principe uit het geheugen te halen, belangrijk bij vectorberekeningen, die we weer veel bij multimediaprogrammatuur tegenkomen.
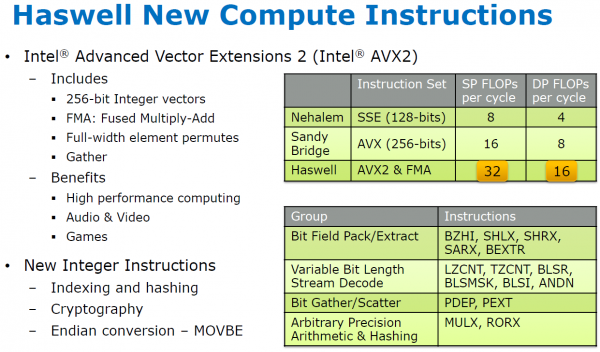
Onderdeel van AVX2 is een door veel developers gevraagde fused multiply-add (FMA) instructie, waarmee in één keer getallen vermenigvuldigd en opgeteld kunnen worden. AMD introduceerde eerder ook al een FMA-instructie bij de Bulldozer kern, maar helaas zijn beide niet compatible. AMD heeft gekozen voor de meer geavanceerde FMA4 implementatie, die kan werken met vier variabelen. Bulldozer kan dus in één keer de instructie D = A x B + C uitvoeren. Intel kiest voor FMA3, met maximaal drie variabelen (C = A x B + C). Echter zelfs deze minder geavanceerde variant kan bij voor AVX2 gecompileerde software voor een aardige prestatiewinst zorgen.
Gebrekkige communicatie
Nieuwe instructies worden pas breed door softwareontwikkelaars toegepast wanneer voldoende mensen er gebruik van kunnen maken. Concreet betekent dit dat nieuwste instructies pas een echte kans van slagen hebben als ze door zowel Intel als AMD worden omarmd. Of ze het willen of niet, de twee processorfabrikanten zijn op dit vlak tot elkaar veroordeeld. De implementatie van fused multiply-add (FMA) is een mooi voorbeeld van hoe gebrekkig de communicatie tussen beide concurrenten kan zijn.
Augustus 2007 kondigde AMD haar voorstel voor de SSE5-instructieset aan, met als onderdeel daarvan instructies met drie variabelen én een FMA3-instructie. SSE5 zou in Bulldozer moeten gaan verschijnen. April 2008 volgde Intel met een aankondiging van AVX, met eveneens 3-operand instructies (maar anders geïmplementeerd) en een 4-variabele variant van FMA, ofwel FMA4. Het was voor AMD reden om de plannen voor Bulldozer weer op de schop te nemen (één van de vele vertragingen) en aan de slag te gaan met een Bulldozer-architectuur met ondersteuning voor AVX en FMA4. Terwijl men daar aan werkte, kondigde Intel in december 2008 de overstap aan van FMA4 naar FMA3. Voor AMD was er geen weg terug meer en in mei 2009 kondigde AMD aan dat Bulldozer over AVX en FMA4 zou beschikken. Uiteindelijk bleek dat toen Intel AVX bij Sandy Bridge introduceerde, FMA er nog geen onderdeel van was. AMD liep op dit vlak dus voor, maar moest noodgedwongen de tweede generatie Bulldozer (Piledriver) ook geschikt maken voor FMA3, om compatible te zijn met Intel Haswell.
Security
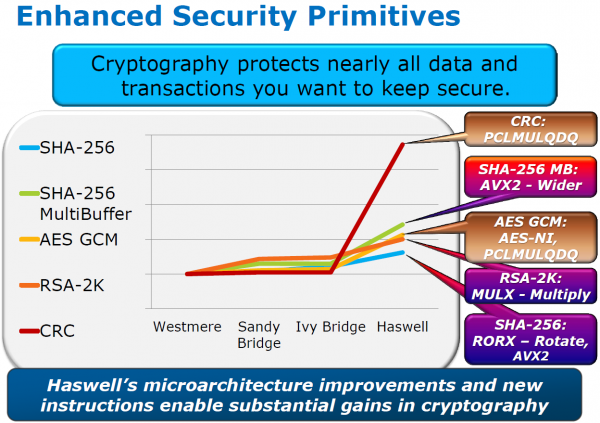
Naast de AVX2 extensies heeft Intel ook nog een aantal nieuwe instructies aan Haswell toegevoegd die encryptie-algoritmes kunnen versnellen. Veelgebruikte algoritmes als SHA-256, RSA en AES profiteren daarvan. De grootste prestatiewinst is te verwachten bij het berekenen van CRC-data; wanneer software van de nieuwe instructies gebruik maakt, zou dat tot meer dan 4x sneller kunnen gaan dan op een Ivy Bridge CPU. Nu steeds meer data op internet versleuteld wordt - denk aan VPN-verbindingen, gecodeerde video-conferencing streams, HTTPS-websites, etc. etc. - vormen deze nieuwe instructies voor flink snelheidsverbeteringen.