Optimalisaties
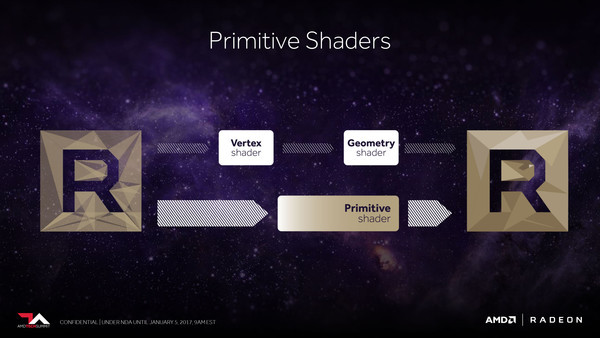
Ook dieper in de GPU zijn er diverse verdere optimalisaties te vinden. Allereerst heeft AMD binnen de Vega-architectuur een nieuwe, volledig programmeerbare geometrie pipeline ontwikkeld, getiteld primitive shader. In de traditionele 3D-pipeline komt deze in plaats van de vertex en geometry shaders en pakt dus al het werk op dat te maken heeft met het uit driehoeken opbouwen van de scene. Bij bestaande software kan Vega ook prima conventionele code vertex en geometery shader code verwerken, maar dankzij uitbreidingen op de Vulkan en wellicht in de toekomst ook DirectX API's zijn de compute units ook efficiënter volgens de nieuwe methode aan te sturen. Laat duidelijk zijn; het gaat nog altijd gewoon om de bestaande rekeneenheden (compute units) die op meerdere manieren aangestuurd kunnen worden, maar dankzij de nieuwe methode is er wat minder overhead en kan er efficiënter gewerkt worden.
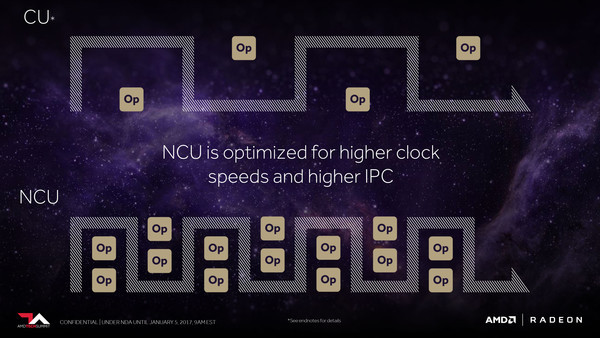
De compute units, de feitelijke rekeneenheden waarvan er duizenden binnen de chip aanwezig zijn, zijn ook vernieuwd en noemt men nu Vega NCU, waarbij NCU staat voor Next-generation Compute Unit. Een belangrijke verbetering is dat de CU's niet enkel geoptimaliseerd zijn voor verwerking van 32-bit data, maar nu ook op dubbele snelheid 16-bit data en ook op viervoudige snelheid 8-bit data kunnen verwerken. Deze aanpassing is vooral van belang om de GPU's geschikter te maken voor compute workloads, zoals het op de eerste pagina van dit artikel genoemde machine learning. Volgens AMD kunnen ook gamers er in potentie van profiteren. Sommige niet graphics-gelerateerde code van game-engines, zoals bijvoorbeeld AI (articificiële intelligentie) algoritmes, zouden ook in 16-bit of 8-bit uitgevoerd kunnen worden en daarvoor veel sneller verwerkt worden. Of developers dat ook daadwerkelijk gaan doen valt te natuurlijk te bezien. Men noemt deze functie Rapid Packed Math.


Verder geeft AMD aan dat de Vega NCU's zijn geoptimaliseerd voor hoge klokfrequenties en een hogere IPC, zonder dat verder concreet te maken. Toch durven we wel een schatting te maken. Bij de introductie van de Radeon Instinct producten gaf AMD aan dat de op Vega-chip gebaseerde Instinct kaart ca. 25 TFlops rekenkracht biedt bij 2x packed math, ofwel bij 16-bit data. We weten nu dat Vega 16-bit data twee keer zo snel verwerkt als 32-bit, dus voor 32-bit data zal de rekenkracht circa 12,5 TFlops zijn. Uit de vele geruchten die er over Vega rondgaan - en laat duidelijk zijn, dit is niet bevestigd - zou de GPU in totaal 4096 compute units krijgen. Op die manier zouden we uitkomen op circa 1500 MHz ( 12,5 / 4096 / 2 * 1000). Dat is inderdaad een aanzienlijk hogere klokfrequentie dan gebruikelijk bij de huidige AMD GPU's.
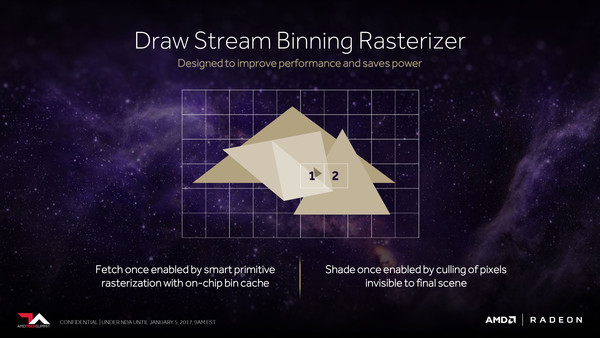
Ook de manier waarop de Vega chips de uiteindelijke pixels berekenen is geoptimaliseerd. Er zijn verbeterde algoritmes aanwezig die vooraf bepalen of een pixel wel of niet zichtbaar is en de verdere verwerking ervan stopzetten wanneer dat niet het geval gaat zijn. Hiermee probeert men het onnodig meerdere keren renderen van pixels binnen een frame zo veel mogelijk te voorkomen. De render backends staan in de nieuwe architectuur in directe verbinding met de L2-cache en kunnen daar op hoge snelheid mee communiceren. Dit heeft volgens AMD een groot positief effect op de prestaties bij game-engines die van deferred rendering gebruik maken. En dat zijn er voldoende! CryEngine 3, Unity, Unreal Engine 4 en AnvilNext maken alle in meer of mindere mate gebruik van deferred rendering. Hoe groot de prestatiewinst exact is, wil AMD echter nog niet prijsgeven en zal ook grotendeels afhankelijk zijn van drive optimalisaties.