

De diepte in: de Broadwell-E cores
Broadwell is zoals geschreven een tick en dus in de basis een bestaande architectuur uitgevoerd op een nieuw productieprocedé. Het maakt dat de architectuur van de cores is afgeleid van die van Haswell en slechts op kleine punten verschilt. De belangrijkste aanpassingen zetten we nog eens op een rij.
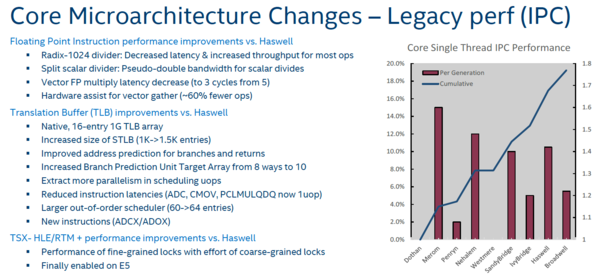
Voor bestaande code belooft Intel een gemiddelde IPC - instructions per clock - toename van zo'n vijf procent ten opzichte van de vorige generatie. Dat betekent dus dat bij een identiek aantal cores en een identieke klokfrequentie bestaande workloads gemiddeld zo'n 5% sneller verwerkt zullen worden. Wanneer software gebruikmaakt van nieuwe instructies, waarover verderop meer, kan de prestatiewinst veel groter zijn.
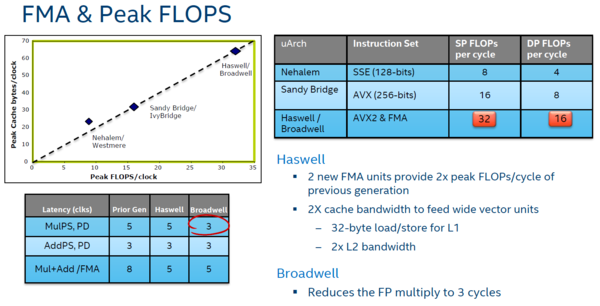
Onder meer op het vlak van floating point berekeningen zijn verdere optimalisaties doorgevoerd. Bij de Haswell generatie wist Intel de verwerktijd voor een FMA (Fused Multiply Add) instructie, ofwel een combinatie van vermenigvuldigen en optellen (A + B x C) terug te brengen van acht naar vijf klokslagen. Voor het doen van vermenigvuldigingsoperaties werd hetzelfde transistorpad gebruikt (maar dan zonder optelling), waardoor ook vermenigvuldig (MUL) instructies een latency van 5 kloks hadden. Die is bij Broadwell gereduceerd tot drie. De piek rekenkracht gemeten in FLOPS is identiek gebleven. Dankzij de AVX2 instructieset kan Broadwell net als Haswell 256-bit floating point getallen in één keer verwerken. Dankzij FMA, wat in feite twee floating point instructies in één is, en met twee AVX2-geschikte execution units per core, komen we zo op 2 x 2 x 256 = 1024 bits per keer, ofwel 16 double-precision (64-bit) floating-point operaties per klokslag.
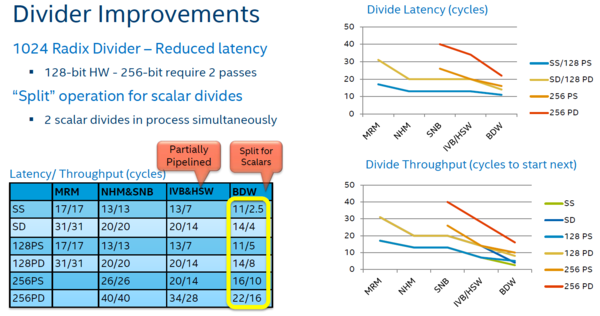
De prestaties bij het deel algoritmes zijn ook verder toegenomen. De zogenaamde 1024 Radix Divider is bij double-precision instructies in latency verlaagd van 20 naar 14 klokslagen en voor andere getaltypes zijn er vergelijkbare afnames. Maar vooral het aantal klokslagen tussen twee opeenvolgende delingen is flink afgenomen.
De 5% wordt verder bewerkstelligd door verschillende andere zaken, zoals een grotere out-of-order scheduler (waardoor een groter aantal instructies in geoptimaliseerde volgorde kan worden uitgevoerd), betere voorspelling van geheugenadressen bij vertakkingen in software, een grote buffer voor het bijhouden van virtuele geheugenadressen en andere zaken.
In een eerdere test op basis van desktop Broadwell processors zagen we al dat de Broadwell architectuur in de Cinebench workload ten opzichte van Haswell een IPC-verbetering van zo'n 3,5% biedt. Bij een video-compressie workload was het verschil nog kleiner. Bij die test wisten we de 5% dus in ieder geval niet te behalen, hoewel die steekproef veel te klein is om een definitieve uitspraak over de IPC toename te doen. Bij onze test van de Broadwell serverprocessors zagen we gelijkaardige toenames. Hoe het ook zij; verwacht op dit vlak geen wonderen, zoals gebruikelijk bij een tick. Winst zit hem voornamelijk in extra cores, hogere klokfrequenties en meer overklokpotentieel.
Grotere prestatiewinsten zijn te behalen wanneer gebruikgemaakt wordt van nieuwe instructies in nieuw ontwikkelde en/of opnieuw gecompileerde software. Zo is Broadwell de eerste generatie waarbij TSX daadwerkelijk is ingeschakeld én zijn er nieuwe instructies voor security gerelateerde algoritmes. TSX ofwel Transactional Memory Extensions is echter een technologie die primair voor server workloads interessant is. In onze Broadwell-EP server review is dit uitgebreider beschreven. De versnelling voor encryptie-algoritmes zal ook primair bij servers voor winst zorgen, maar nu meer en meer communicatie over internet versleuteld is, kan het ook voor desktops effect hebben.
Een van de zaken die is verbeterd is dat Intel de verwerkingstijd van de zogenaamde PCLMULQDQ instructie, die onder andere gebruikt wordt in AES en CRC algoritmes, heeft teruggebracht van 7 naar 5 klokslagen. De multiplier throughput van deze instructie is verder verdubbeld. Het maakt dat AES encryptie zo'n 20% sneller kan worden uitgevoerd en CRC's zelfs bijna twee keer sneller worden uitgevoerd. Verder heeft Intel twee specifiek op security algoritmes gerichte nieuwe instructies geïntroduceerd, ADCX en ADOX. Wat deze precies doen valt buiten het bereik van dit artikel, maar deze instructies kunnen onder meer RSA encryptiealgoritmes flink versnellen, tot meer dan 50%.
1 besproken product
| Vergelijk | Product | Prijs | |
|---|---|---|---|

|
Intel Core i7 6950X Boxed
|
Niet verkrijgbaar |







