

Praktijkvoorbeeld
Een van de bekendste voorbeelden van hoe een kwantumcomputer grote snelheidsverbetering kan bieden, is Grover’s algorithm. Vaak wordt het beschreven in termen van telefoonboeken, maar de principes gelden voor elke ongesorteerde database. Stel dat je een telefoonnummer hebt en je wilt de naam hierbij opzoeken, dan zal dit nogal tijdrovend zijn. Door het gebrek aan een organisatorisch principe zal je gemiddeld namelijk de helft van het telefoonboek moeten doornemen voordat je bij toeval op het juiste antwoord terecht komt.
Grover’s algorithm pakt het op een andere manier aan, met behulp van kwantumprincipes. Allereerst geef je een dataset (quantum register) de superpositie van alle waardes in de database. Dit betekent dat het register tegelijkertijd al deze waardes bevat, maar op het moment van het uitlezen kan je uiteraard maar één waarde krijgen. Om de gewenste waarde sterker te maken (en dus waarschijnlijker bij het uitlezen) gebruikt het algoritme constructieve interferentie, terwijl de onjuiste waardes zwakker worden gemaakt met destructieve interferentie. Denk aan hoe twee luidsprekers met dezelfde geluidsgolf meer geluid creëren (constructieve interferentie), en hoe twee golven van gelijke omvang elkaar kunnen opheffen op het moment dat ze contact maken (destructieve interferentie). Aangezien de kwantum superpositie een golf is, kan dat hiermee ook. In de praktijk betekent dit in kwantumtermen dat de waardes bij uitlezing respectievelijk waarschijnlijker en minder waarschijnlijk worden.
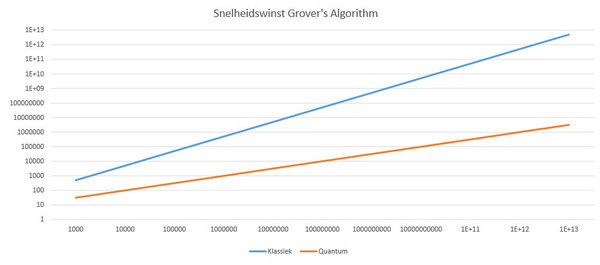
De snelheidswinst die je kan halen met Grover’s algorithm neemt sterk toe met het aantal waardes in de database. Horizontaal zie je het aantal waardes en verticaal het aantal pogingen dat een systeem nodig heeft om op het juiste antwoord te komen. Let op: de schaal is logaritmisch.
Na een bepaald aantal stappen krijg je bij het uitlezen de waarde waarnaar je op zoek was. In plaats van dat je gemiddeld de helft van de waardes hebt moeten doorlopen, is dat slechts de wortel van het aantal waardes. De winst neemt dus toe met de omvang van de database. Bij een database met een miljoen waardes gaat het 500 keer sneller, met een miljard waardes maar liefst 15811 keer sneller. Overigens is de snelheidswinst bij sommige andere algoritmes nog veel groter.







