

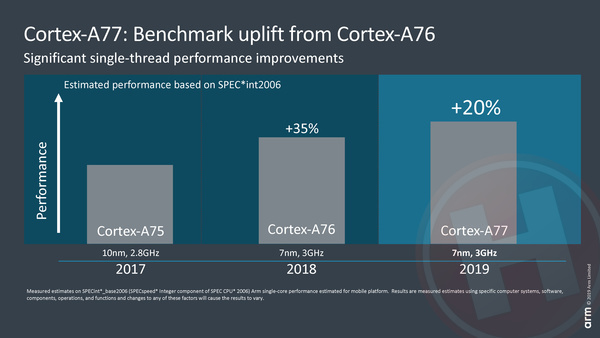
Cortex-A77: 20% sneller is de belofte
De Cortex-A76 van vorig jaar was een van de grootste stappen die cpu-ontwikkelaars van ARM de afgelopen jaren hebben bewerkstelligd. Het was een vrijwel volledig vernieuwde implementatie van de 64-bit ARMv8 architectuur, met een flinke prestatiewinst ten opzichte van voorloper Cortex-A75 tot gevolg. De nieuwe Cortex-A77 is in principe een doorontwikkeling van de A76, al geven we de nieuwe core met die omschrijving vermoedelijk wat te weinig eer. De beloofde 20% prestatiewinst, mocht die in de praktijk inderdaad zo hoog blijken te zijn, is immers alles behalve klein bier. Voor de duidelijkheid: die 20% ten opzichte van de A76 is met identieke klokfrequentie en een identiek productieprocedé.
Het verbeteren van een cpu-microarchitectuur is in de basis een iteratief proces van telkens een bottleneck opsporen, die oplossen en vervolgens bekijken wat de volgende bottleneck is. Zo kun je er bijvoorbeeld voor kiezen om het aantal rekeneenheden te verhogen, maar dan kan het bijvoorbeeld zijn dat bepaalde datapaden binnen een processor niet toereikend zijn om instructies of data snel genoeg tussen de verschillende chiponderdelen te verplaatsen. Zijn alle datapaden verbreed of versneld, dan zou het weer kunnen dat juist de onderdelen die instructies of data moeten ophalen uit het geheugen moeten worden verbeterd.
Chipoppervlak en stroomverbruik zijn heilig
In principe zou je kunnen denken dat het sneller maken van een cpu-microarchitectuur vrij simpel kan door simpelweg “van alles meer” te implementeren. In theorie is dat natuurlijk ook zo, maar in de praktijk zijn er twee beperkingen die juist voor ARM heilig zijn: chipoppervlak en stroomverbruik. Hoe groter een chip, hoe duurder deze is om de produceren en hoe lastiger deze is om te gebruiken in kleine, mobiele devices. En dat het beperken van stroomverbruik bij architecturen die primair bedoeld zijn voor mobiele toepassingen van extreem belang is, vergt natuurlijk geen verdere uitleg. ARM gebruikt zeer strikte marges. De exacte percentages wil men niet prijs geven, maar je mag er bijvoorbeeld van uitgaan dat een aanpassing die x % procent prestatiewinst oplevert, maximaal bijvoorbeeld x/4 % extra stroomverbruik kost. De heilige graal is natuurlijk het bedenken van optimalisaties die een microarchitectuur tegelijkertijd sneller én zuiniger maken.
Terug naar de A77. Zoals geschreven is de cpu-core gebaseerd op de Cortex-A76. Net als deze is de A77 gebaseerd op versie 8.2 van de ARM-architectuur en geschikt voor zowel 32-bit (AArch32) als 64-bit (AArch64) software. Zoals bekend kunnen ARM’s snelle cores binnen een SoC gecombineerd worden met langzamere, maar ook zuinigere cores in zogenaamde big.LITTLE danwel DynamiQ configuraties. ARM heeft voor komend jaar geen nieuwe “kleine” core op de rol, wat betekent dat de Cortex-A76 net als voorlopers A75 en A73 gecombineerd kan worden met Cortex-A55 kernen. Net als bij de A76 is het aan de uiteindelijke SoC-ontwikkelaar om te kiezen hoeveel cachegeheugen de cores tot hun beschikking krijgen. Voor L2-cache kan er gekozen worden tussen 256 kB of 512 kB en de door meerdere cores gedeelde L3-cache kan variëren van 1 MB tot 4 MB.

De A77 is op “honderden” plekken verbeterd ten opzichte van de A76, maar een aantal zaken springt eruit. Zo heeft ARM in de zogenaamde front-end van de cpu voor het eerst een macro-op cache toegevoegd, een onderdeel waarin gedecodeerde instructies opgeslagen worden voor het geval dat ze later nog een keer gebruikt worden. De pipeline van de processor heeft ARM verder verbreed, zodat er iedere klokslag zes in plaats van vier macro-ops van het ene naar het volgende onderdeel van de chip kunnen gaan. Verder is het aantal instructies waarvan de micro-architectuur de volgorde kan omwisselen om deze geoptimaliseerd uit te voeren verder verhoogd. Bij de execution units, de uiteindelijke onderdelen waar daadwerkelijke berekeningen worden uitgevoerd, zijn er twee toegevoegd.
Is dit voor jou Chinees? Op de volgende pagina bespreken we deze verbeteringen in detail.







