

De Athlons Architectuur
Na de uitleg over de specificaties en systeembus van de Athlon wordt het nu tijd om naar de werkelijke architectuur van de CPU te gaan kijken. Onderstaande afbeelding toont een blokschema van de CPU:
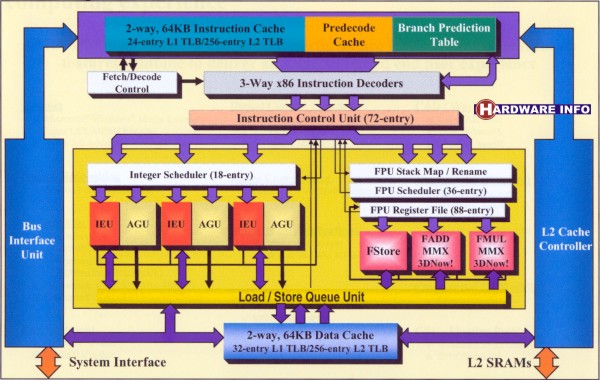
Kenners zullen meteen helemaal wegkwijnen bij deze afbeelding. Voor de rest zal ik proberen enige duidelijke uitleg bij het schema te geven.
We beginnen helemaal linksonder: hier is duidelijk de verbinding met de system interface (met de systeembus dus) te zien. Door deze interface gaan alle binnenkomende instructies en data, maar gaat uiteraard ook alle uitgaande data. De Bus Interface Unit (links) zorgt voor de aansturing van de bus en leidt de binnenkomende informatie door naar de juiste plaatsen. Instructies gaan naar boven (let op het eenrichtingsverkeer daar! Instructies gaan namelijk alleen maar IN een processor, niet er uit) en data gaat beneden. Beide komen uit bij de 64 KB Level1 cache. Merk op dat beneden bij de data wel overal twee richtingsverkeer aanwezig is. Data moet de CPU namelijk wel zowel IN als UIT kunnen. De Data Cache staat uiteraard in verbinding met de functionele units, om verwerkte data op te halen of juist om data aan te geven die nodig is voor een bewerking. Aan de rechterkant is de L1 Data Cache ook verbonden met de L2 Cache Controller, die rechtsonder weer een verbinding heeft naar de L2 Cache. Data waarvan de CPU denkt dat die dadelijk weer vereist is wordt zolang opgeslagen in dit relatief snelle (t.o.v. het standaard geheugen) L2 Cache.
We kijken nu weer boven bij de instructies verder. Nadat de instructies in de Instructie L1 Cache terecht zijn gekomen haalt de Fetch/Decode Controller deze er weer uit. Aangezien x86 instructies meestal lange complexe instructies zijn rafelen de Instruction Decoders (midden boven) deze ingewikkelde CISC (Complex Instruction Set) instructies uiteen in een aantal makkelijkere RISC (Reduced Instruction Set) instructies. Deze simpelere operatie (MacroOPS genoemd) kunnen de functionele units direct verwerken. Zoals te zien heeft de AMD Athlon drie van deze Instrucion Decoders. Hoewel Intel er ook drie heeft geplaatst in de Pentium III is er toch een voordeel bij de AMD Athlon: van de drie decoders in de Pentium III is er maar één gemaakt voor het decoderen van zeer complexe instructies. Beide anderen kunnen alleen simpelere instructies omzetten naar simpele MarcoOPS. In het beste geval kunnen dan wel drie instructies per klokslag vertaald worden, maar in de praktijk wordt dit bijna nooit behaald. De drie decoders van de AMD Athlon zijn echter wel alle drie ook geschikt voor zeer complexe instructies, zodat de tijd die nodig is voor het decoderen van een lange reeks coplexe instrucites bij de AMD Athlon een stuk lager ligt.
I.s.m. de Branch Prediction Table wordt er besloten welke programma takken wel en niet worden verwerkt. (Zie ons Intel Merced artikel voor meer informatie over Branch Prediction.) Aangezien de Branch Target Buffer maarliefst 2048 entries diep is schat AMD dat in 95% van de gevallen de juiste brnach genomen wordt. De nu klaar gestoomde MacroOPS worden door de Instruction Control Unit de instructies verdeeld over de 9 functionele units, die we al besproken hebben bij de specificaties. Deze Instruction Control Unit is 72 entries diep, dus er kunnen 72 MarcoOPS tegelijkertijd klaar gezet worden. Ter vergelijking: de unit van de Pentium III kan maar 20 operaties tegelijkertijd verwerken. Terug naar de 9 functionele units: Links zijn de 3 Integer Units en de 3 Address Generation Units te vinden, terwijl rechts de 3 Floating Point units te vinden zijn.
Alle Integer resp. Address Generation Units zijn identiek, en een 18 entries diepe scheduler zorgt daar voor een juiste verdeling van de instructies. Uiteraard zijn al deze functionele units volledig gepipelined (zie ons pipelining artikel) en staan ze met elkaar in verbinding voor het geval dat de bewerking in de ene afhankelijk is van de uitkomst van een bewerking in de ander. Aan de rechter kan zien we ook een Scheduler voor de Floating Point instructies. Deze worden verdeeld over de drie gepipelinede Floating Point units. Alleen de tweede en de derde zijn ook geschikt voor 3DNow! en MMX bewerkingen. De tweede is verder geoptimaliseerd voor het optellen van floating point getallen en de derde voor het vermenigvuldigen daarvan. De FPU Stack Map / Rename zorgt voor een goed verloop van loops en voert zaken uit die te vergelijken zijn met het Register Renaming systeem van de Intel Merced.
De Load / Store Queue Unit zorgt voor de juiste aan en afvoer van data tussen de functionele units en de L1 Data Cache.
Iedereen begrijpt nu hoe de AMD Athlon processor werkt ;-)







