

Blokdiagram
Om de dieper verscholen verschillen tussen Penryn en Nehalem boven water te krijgen, werpen we een blik op het blokdiagram van de nieuwe architectuur. Op onderstaande slide zie je hoe de architectuur van Nehalem er schematisch uitziet.
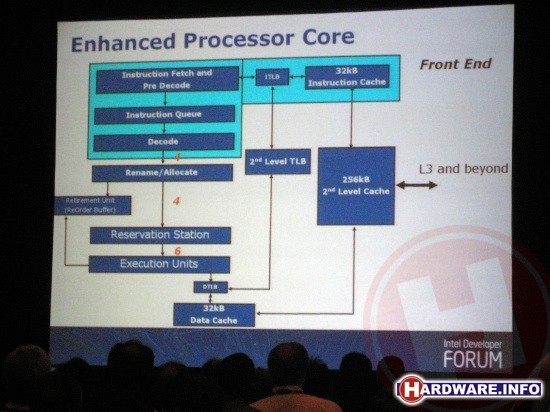
Het blok linksboven zorgt voor het ophalen, queuen en decoderen van alle binnenkomende instructies. De Rename/Allocate en Reservation Station blokken daaronder passen de volgorde van de instructies daarna zo aan, dat deze op een zo efficiënt mogelijke volgorde kunnen worden uitgevoerd. De daadwerkelijke berekeningen worden uitgevoerd door de execution units. Zoals op het schema te zien is de weg van het bovenste blok tot en met het reservation station zogenaamd 4-wide, wat betekent dat er telkens vier instructies per klokslag doorgevoerd kunnen worden. Naar de execution units kunnen zelfs zes instructies per klokslag worden doorgestuurd, wat één van de eerste architecturele verbeteringen ten opzichte van Penryn is. Hier komen we verderop op terug.
In het blokschema zien we verder dat de instructie fetchers zijn verbonden met 32 kB L1 instructiecache en verbonden aan de executions units zien we juist 32 kB L1 datacache. Beide caches staan weer in verbinding met 256 kB L2-cache die iedere core exclusief tot zijn beschikking heeft. Die L2-cache dient weer als buffer voor de onder alles cores gedeelde L3-cache.
Op de komende paar pagina's worden de verschillende onderdelen van bovenstaand verder uitgelegd en beschrijven we wat de verschillen zijn met de bestaande core architectuur.






