Branch prediction en execution units
Een belangrijke manier om de prestaties van een processor te verbeteren is het zo goed mogelijk voorspellen van vertakkingen in programmatuur. Immers; moderne processors verwerken instructies niet noodzakelijkerwijs in de volgorde waarin ze binnenkomen en daardoor kan het zijn dan er al gewerkt moet worden aan instructies die nog afhankelijk zijn van een eerdere instructie, die pas op een later tijdstip wordt uitgevoerd. Wanneer er in zo'n geval een vertakking in een programma ontstaat, zal de processor zo goed mogelijk een gok doen welke tak de meeste kans van slagen heeft. Brand predictors zijn tegenwoordig zo goed dat er nog maar zelden mis gegokt wordt. Dat is maar goed ook, want een branch miss betekent dat de hele pipeline vol kan zitten met instructies die niet meer nodig zijn en dat het heel wat klokslagen kan duren eer weer een juiste instructie uit de processor rolt.
Intel heeft op een aantal manieren de branch prediction in Nehalem verder verbeterd. Een van de belangrijkste manieren bestaat uit het al beginnen met het voorspellen zodra instructies in L2-cache aankomen. Op dit niveau heeft de processor een breder kijkveld en kan er zodoende een nog betere beslissing worden genomen.

Dan de execution units; zoal op de vorige pagina al beschreven is er bij Nehalem een zesvoudig pad van het reservation station naar de daadwerkelijke rekeneenheden van de core. Bij de Core architecuur waren dat er vier. Achter elk van deze zes ingangen, zitten één of meerdere rekeneenheden. Poort 2, 3 en 4 zijn alleen geschikt voor geheugenadres operaties, poort 0, 1 en 5 zijn ook geschikt voor integer of floating point berekeningen.
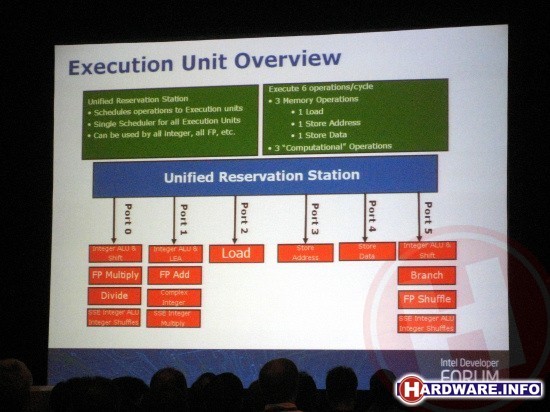
De truc is natuurlijk om ten alle tijden alle vier poorten gevuld te hebben. (Het vullen van vijf of zes is in de praktijk vrijwel onmogelijk, aangezien er tot aan de reservation station slechts vier instructies per klokslag kunnen worden doorgestuurd.) Dat betekent dus dat de processor in ieder moment in tijd in het ideale geval aan de slag moet kunnen vier verschillende bewerkingen, die naast elkaar in de verschillende execution units moeten passen. Geen wonder dus dat een processor zoals eerder gezegd de volgorde van instructies omhusselt om deze in een optimalere volgorde uit te voeren.
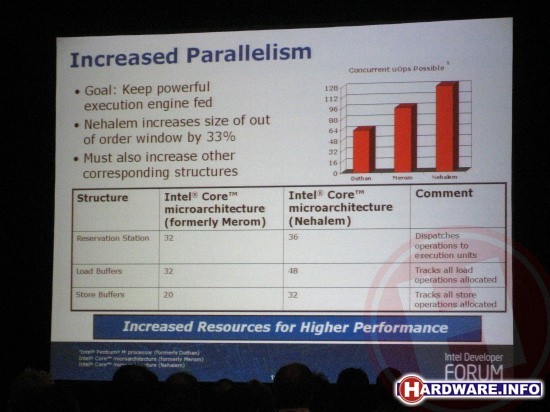
Om in zoveel mogelijk gevallen alle execution units bezig te houden, is bij Nehalem het aantal instructies dat een core tegelijkertijd in z'n achterhoofd kan houden om in geoptimaliseerde volgorde uit te voeren flink verhoogd. Bij de Pentium M was het maximum 64 instructies, bij de Core architectuur werd dat aantal verhoogd naar 96 en nu bij Nehalem zelfs naar 128. Een verhoging van 33% dus. De ruimte in het reservation station is toegenomen van 32 naar 36 instructies.
Het aantal buffers voor load en store operaties is nog meer toegenomen. Het aantal load buffers gaat van 32 naar 48, het aantal store buffers van 20 naar 32. Opnieuw kan dit allemaal in veel gevallen voor aardige prestatiewinsten zorgen.