

Geïntegreerde geheugencontroller
Een bijkomend aspect is de geïntegreerde geheugencontroller van Nehalem. Ook hier heeft Intel meer informatie over bekend gemaakt. We wisten al dat de eerste Nehalem chips die het levenslicht zullen zien, een triple-channel DDR3-geheugencontroller aan boord hebben. Doordat het geheugen rechtstreeks met de processor verbonden is, zijn de latencies veel lager dan bij huidige Intel platformen. Het hele concept van fully buffered DIMM's, zoals dat nu in Intel servers wordt toegepast, is overboord gegooid. Nehalem maakt voor desktop systemen gebruik van standaard DDR3-modules en voor servers van registered varianten.

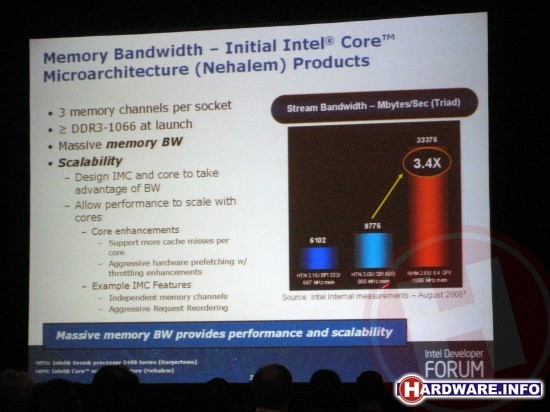
In dual-CPU configuraties is er in feite nu een zes-kanaals geheugencontroller aanwezig. Intels huidige chipset voor quad-core Xeon-processors uit de Core-generatie is beperkt tot vier kanalen. Samen met de lagere latencies en hogere doorvoersnelheid van DDR3, heeft dit een gigantische prestatiewinst op geheugenvlak voor het nieuwe platform tot gevolg. Zo toonde Intel de resultaten van de veel gebruikte Stream geheugen benchmark. Een bestaande state-of-the-art server met twee Harpertown Xeon processors met 1600 MHz FSB en quad-channel FBDIMM DDR2-800 geheugen behaalt in de benchmark net geen 10 Gigabyte per seconde doorvoersnelheid. Een server op basis van twee Nehalem processors met elk triple-channel geheugen gaat met gemakk de 33 Gigabyte per seconde voorbij. Een stijging van 3,4x! Voor server applicaties die goed schalen met geheugen snelheid (zoals bijvoorbeeld database applicaties) kan de overstap naar Nehalem dus zeer interessant zijn. In feite geeft Intel inmiddels dus ook schoorvoetend toe dat de geheugenarchitectuur die AMD al sinds de Athlon 64 heeft gekozen, de enige juiste is.
Nu ook Intel processors een geïntegreerde geheugencontroller hebben, ontstaat er bij multi-processor systemen een zogenaamde NUMA (Non-uniform Memory Access) geheugen architectuur. Immer; software die fysiek op een bepaalde processor draait kan het best gebruik maken van het geheugen gedeelte dat direct aan de betreffende processor verbonden is, aangezien dat met de laagste toeganstijd benaderd kan worden. Om een andere geheugenpartitie te benaderen, moet er immers via een andere CPU gecommuniceerd te worden. Het besturingssysteem moet hier rekening mee houden en het geheugen zo slim mogelijk indelen.
Hier kan Intel echter profiteren van de wet van de remmende voorsprong. AMD heeft met haar Opterons inmiddels immers al enkele jaren een NUMA geheugen architectuur, met als resultaat dat alle besturingssystemen (Windows, Linux, etc.) er al volledig voor zijn geoptmaliseerd. Intel profiteert daar nu direct van mee.

Interessant is overigens dat zelfs wanneer er gebruik gemaakt wordt van geheugen dat aan een andere processor hangt, de totale wachttijd nog altijd lager is dan bij het huidige Intel platform, waarbij de geheugencontroller in de chipset zit. Dat is te zien in onderstaande grafiek. De meest linkse, oranje balk is de gemiddelde lantency van een bestaand Harpertown platform, genormaliseerd naar 1. De latency als gevolg van de geïntegreerde geheugencontroller is volgens deze Intel benchmarks zo'n 40% sneller. Wanneer er van geheugen van de tweede CPU gebruik gemaakt wordt, gaat dit nog altijd een fractie sneller dan vroeger.








