

Turing-architectuur: nieuwe cores, snellere shaders
De nieuwe GeForce RTX kaarten zijn zoals geschreven gebaseerd op een nieuwe generatie gpu's luisterend naar de naam Turing. De Turing-chips zijn qua opbouw en architectuur drastisch anders dan de Pascal-generatie chips zoals we die kennen van de GeForce GTX 10-serie kaarten. Nvidia spreekt zelf over de "grootste verandering sinds de komst van de volledig programmeerbare Cuda-cores in 2006". Hoewel we dergelijke marketingclaims bij nieuwe producten altijd met een gezonde dosis scepsis tot ons nemen, zijn we het vanuit technisch oogpunt dit keer wel met de fabrikant eens.
Waar gpu's de afgelopen jaren immers bestonden uit honderden en bij high-end exemplaren zelfs duizenden shader cores aangevuld met wat periferie als geheugen- en displaycontrollers, vinden we in de Turing-chips naast conventionele shader-cores ook twee nieuwe type cores: RT-cores voor het versnellen van raytracing en Tensor-cores voor het versnellen van machine learning c.q. kunstmatige intelligentie algoritmes. En alsof dat allemaal nog niet genoeg is, bevat de gpu ook nog technologie voor verschillende nieuwe rendertechnieken als mesh rendering (voor scènes met extreem veel detail) en variable rate shading (om beelden niet op het hele scherm in dezelfde resolutie te renderen). Zoals gezegd noemt Nvidia de eigen (software) technologieën om gebruik te maken van de nieuwe mogelijkheden van RT- en Tensor-cores RTX.

De Turing-architectuur bevat een nieuwe architectuur voor de conventionele shader-units, nieuwe RT- en Tensor-cores voor raytracing en AI en daarbovenop nog ondersteuning voor nieuwe rendertechnieken.
Ondersteuning voor real-time raytracing en AI is zonder enige twijfel de allerbelangrijkste vernieuwing bij de Turing-chips. Op de volgende pagina's gaan we uitgebreid in op deze nieuwe mogelijkheden. Dat betekent niet dat er bij de conventionele onderdelen van de chip niets gewijzigd is ten opzichte van de Pascal-generatie. In tegendeel! De Cuda-cores, maar bijvoorbeeld ook het geheugen zijn flink versneld.

Turing SM's: integer en floating-point operaties tegelijk
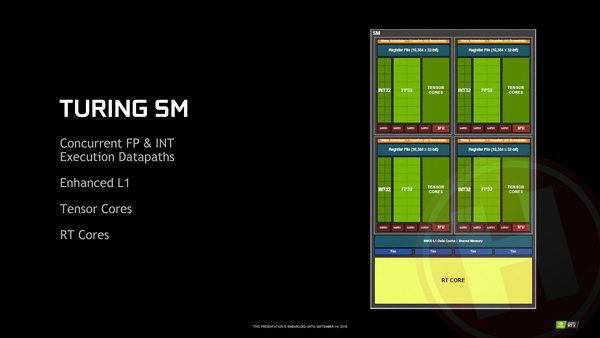
Net als Nvidia laatste paar generatie gpu's zijn de Turing-chips opgebouwd uit meerdere SM's ofwel Streaming Multiprocessors. Zo'n SM is een combinatie van een groot aantal cores en een stuk door deze eigen cores gedeeld cache-geheugen. De verschillende SM's binnen een gpu werken in principe onafhankelijk van elkaar: de ene SM kan bezig zijn met de ene taak, terwijl de andere SM een andere taak verwerkt. De technologie om taken aan de uiteindelijke rekeneenheden toe te wijze, de zogenaamde dispatchers, zijn dan ook binnen een SM verwerkt. De grootste Turing chip, de TU102, heeft in totaal 72 van deze SM's aan boord, waarvan er bij de GeForce RTX 2080 Ti overigens 68 (94%) zijn ingeschakeld.
Binnen een SM zitten traditioneel tussen shader-cores (ofwel Cuda-cores zoals Nvidia ze zelf het liefst noemt), cache-geheugen, texture-units en wat onderdelen om dat alles aan elkaar te knopen. Dat is nog steeds het geval: iedere SM bevat 64 shader-cores, vier texture units en 96 kB L1-cache (waar over verderop meer). Daarnaast bevat iedere SM een RT-core voor raytracing en acht Tensor-cores voor AI, waarvan we de eigenschappen verderop in dit artikel uit de doeken doen.
Shader core vernieuwing
De klassieke shader cores zijn door Nvidia dus ook onder handen genomen. Traditioneel zijn shader-units 32-bit floating-point rekeneenheden en dat is niet voor niets: zo'n beetje alle berekeningen die nodig zijn binnen traditionele 3D-rendering zijn floating point. Nu gpu's ook voor meer en meer taken worden ingezet dan louter 3D-rendering (ook binnen games), moeten de cores ook steeds vaker integer (gehele getallen) berekeningen doen. Met wat kunstgrepen kun je een floating point rekeneenheid integers laten verwerken, maar dat is niet bijster efficiënt, want een specifieke integer-unit kan veel kleiner en zuiniger zijn. Geen wonder ook dat je in CPU's binnen iedere core ook losse integer en floating point verwerkingseenheden hebt.
Dát principe heeft Nvidia bij Turing nu ook toegepast; naast 64 floating point rekeneenheden bevat iedere SM nu ook 64 integer rekeneenheden. De winst zit hem erin dat wanneer een bepaalde workload zowel floating-point als integer berekeningen heeft, deze gelijktijdig uitgevoerd kunnen worden. Hierdoor is het maximale aantal instructies dat een Turing SM per seconde kan uitvoeren in theorie dus een stuk hoger dan bij Pascal, en dat is nog los van de nieuwe RT- en Tensor-cores.
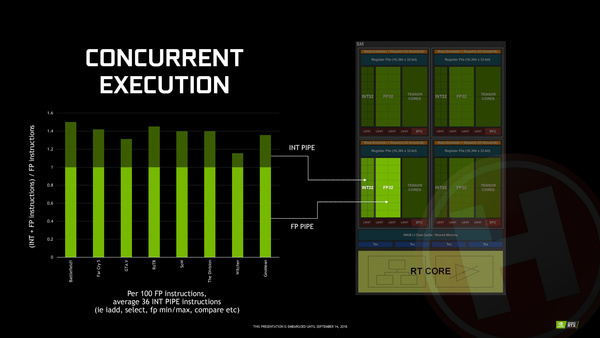
Nvidia heeft becijferd dat in courante games er op iedere 100 floating point instructies gemiddeld ook zo'n 36 integer instructies uitgevoerd moeten worden. Of dat klopt kunnen we niet verifiëren, maar hoe dan ook is het gelijktijdig kunnen uitvoeren van integer en floating point instructies volgens Nvidia één van de, zo niet dé belangrijkste reden waarom de nieuw GeForce RTX kaarten ook in bestaande games (dus zonder raytracing of andere moderne poespas) aanzienlijk sneller zijn dan hun voorlopers. Afhankelijk van de game kunnen instructies tot zo'n 50% sneller uitgevoerd worden op deze manier.
Niet alles tegelijkertijd
Waar de Turing SM's dus wél integer en floating point instructies tegelijkertijd kunnen uitvoeren, is het niet zo dat letterlijk alle onderdelen van de SM tegelijkertijd actief kunnen zijn. Van de driehoek shader-cores, Tensor-cores en RT-core kunnen in de praktijk slechts twee onderdelen daadwerkelijk tegelijkertijd taken uitvoeren, waarbij de bottleneck enerzijds bij de dispatcher ligt, maar vermoedelijk ook simpelweg bij het stroomverbruik van de gehele gpu in het theoretische geval dat alle onderdelen van alle SM's tegelijkertijd vol gas aan het werk zijn. Hier ligt dus duidelijk nog ruimte voor verbetering bij de volgende generatie gpu's.
3 besproken producten
| Vergelijk | Product | Prijs | |
|---|---|---|---|

|
Nvidia GeForce RTX 2070 8GB
|
Niet verkrijgbaar | |

|
Nvidia GeForce RTX 2080 8GB
|
Niet verkrijgbaar | |

|
Nvidia GeForce RTX 2080 Ti 11GB
|
Niet verkrijgbaar |







