

Snellere caches, sneller geheugen
Het blijft niet bij de nieuwe type cores en de opdeling van integer en floating point operaties voor conventionele shader-cores: Nvidia heeft namelijk ook de cache-architectuur drastisch aangepakt.
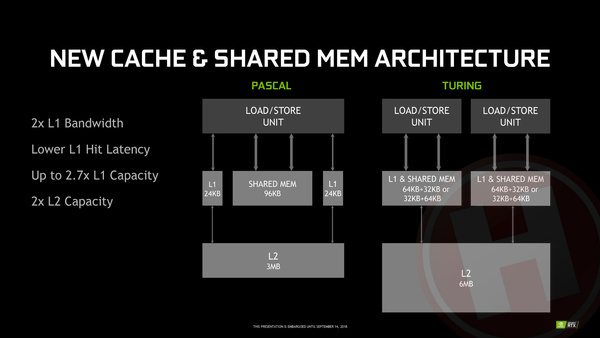
Binnen de Pascal-architectuur had iedere SM 24 kB L1-cache voor instructies, 24 kB L1-cache voor data en daarnaast nog 96 kB gedeelde geheugen. Deze L1-cache werkt als traditionele cache voor het geheugen, waarvoor je als programmeur niets hoeft te doen; Nvidia's eigen algoritmes zorgen ervoor dat wanneer data naar het vanuit de rekeneenheden bekeken relatief langzame GDDR-geheugen moet worden weggeschreven, deze eerst naar de extreem snelle L1-cache gaat (en daarna nog langs L2), zodat de cores meteen door kunnen met andere taken en de data op de achtergrond kan worden getransporteerd naar de uiteindelijke bestemming. Even zo zorgen pre-fetchers ervoor dat data waarvan de gpu verwacht deze spoedig nodig te hebben alvast vanuit het geheugen naar L2- of zelfs L1-cache wordt opgehaald.
Shared memory 2.0
Het gedeelde geheugen werkt nu anders: dit was bij Pascal een (ten opzichte van de L1-cache) relatief groot stuk, 96 kB in totaal, bloedsnel geheugen binnen de SM's dat door software ontwikkelaars zelf beheerd kan worden. Op die manier kon je als developer van een game engine of een GPgpu-applicatie dus zelf bepalen welke data zeer dicht bij de rekeneenheden blijft, wat wanneer je je applicatie goed ontwerpt voor flinke prestatiewinst zorgt. Het voordeel van het gedeelde geheugen is direct ook het nadeel: maak je er als developer geen expliciet gebruik van, dan zit het snelle geheugen er voor niets.
Vandaar dat Nvidia dit bij de Turing-generatie heeft aangepast. Binnen iedere SM zitten nu twee blokken van 96 kB die flexibel ingericht kunnen worden als 32 kB L1 en 64 kB gedeelde geheugen of juist 64 kB L1 en 32 kB gedeeld geheugen. Wanneer een developer dus niet expliciet gebruik maakt van de shared memory-functionaliteit, heeft de applicatie in elk geval profijt van een totale L1-cache grootte die 2,7x groter is dan voorheen (128 kB ten opzichte van 48 kB). Daar komt bij dat de bandbreedte van de L1-cache is verhoogd én de latency is verlaagd.
Meer L2 cache
Vanuit de L1-cache wordt niet direct naar het GDDR-geheugen gecommuniceerd, daar tussen zit bij de Nvidia kaarten nog een grotere, tussen alle SM's gedeelde L2-cache. Die is bij Turing vergroot van 3 MB naar 6 MB. Al met al betekenen deze aanpassingen dat shader cores veel sneller over data kunnen beschikken en de kans dat ze bij een cache miss op langzaam GDDR-geheugen moeten wachten, veel kleiner is.
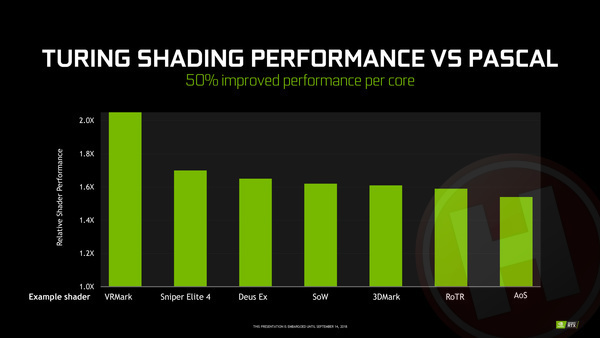
Dankzij de op de vorige pagina beschreven verbeteringen binnen de shader-cores, aangevuld met de snellere caches, belooft Nvidia bij Turing gemiddeld zo'n 50% betere prestaties per core. Wederom, dat is dus zonder nieuwe zaken als raytracing.
GDDR6
Als een cache-miss toch plaatsvindt, is dat minder erg dan bij de vorige generatie want de Turing-chips zijn de eerste gpu's met ondersteuning voor het nieuwe, beduidend snellere GDDR6-geheugen.
GDDR6 is een doorontwikkeling van GDDR5 en biedt nog hogere snelheden: de geheugen-interface werkt met 14 gigabit per seconde. In de grootste Turing-chip, de TU102, zitten 12 32-bit GDDR6-controllers, goed voor 384-bit totale busbreedte. Bij de RTX 2080 Ti zijn er daarvan 11 ingeschakeld, zodat je op 352-bit komt. De TU104 van de RTX 2080 en 2070 heeft een 256-bit (8x 32-bit) geheugencontroller. Al met al moet voor beide gpu's de overstap van GDDR5 naar GDDR6 voor zo'n 25% hogere geheugenbandbreedte zorgen.
Daarnaast heeft Nvidia haar lossless compressiealgoritmes voor alle geheugentoegang verbeterd. Afhankelijk van de game zou de totale effectieve geheugenbandbreedte daardoor zo'n 40% tot in extreme gevallen zelfs 60% hoger kunnen zijn dan bij Pascal.
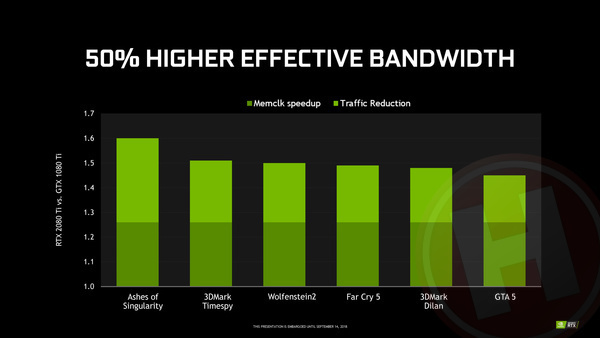
Dankzij het snellere GDDR6-geheugen én betere compressie, is er in de praktijk zo'n 50% hogere geheugenbandbreedte beschikbaar.
3 besproken producten
| Vergelijk | Product | Prijs | |
|---|---|---|---|

|
Nvidia GeForce RTX 2070 8GB
|
Niet verkrijgbaar | |

|
Nvidia GeForce RTX 2080 8GB
|
Niet verkrijgbaar | |

|
Nvidia GeForce RTX 2080 Ti 11GB
|
Niet verkrijgbaar |







