

Cores: MicroOp Cache
Voordat we verder gaan naar de andere onderdelen van de chip, nemen we eerst een diepere duik in de cores. Intel heeft onderhuids immers een aantal belangrijke veranderingen doorgevoerd, enerzijds om AVX mogelijk te maken, anderzijds om de prestaties van de cores te verbeteren. Een voorbeeld van die laatste categorie is een cache voor MicroOps. Even een klein beetje uitleg voor wie deze term minder bekend is: een Intel processor wordt vanuit de software aangestuurd door middel van de X86-instructieset. De X86 architectuur kenmerkt zich door het feit dat er zeer veel instructies zijn, variërend van zeer simpel tot zeer complex. Veel van deze complexe instructies kan een processor niet in één keer uitvoeren; voor verwerking worden ze eerst binnen de CPU opgedeeld in één of meerdere MicroOps.
In onderstaande afbeelding zie je hoe het verwerken van instructies bij huidige Intel processors in het werk gaat. Een wachtrij van instructies die moet worden uitgevoerd wordt opgebouwd in de instructie cache, welke bij alle courante Intel CPU's 32 kilobyte per core is. Vanuit daar gaan de instructies eerst via een predecoder - een onderdeel dat al wat eerste stappen uitvoert - naar een instructie wachtrij en van daar naar een decoder. Deze decoder verwerkt alle X86-instructies naar één of meerder minder complexe MicroOps. Deze MicroOps komen weer een in wachtrij terecht en worden daarna in optimale volgorde (out-of-order in jargon) verwerkt.

In de tweede afbeelding zie je hoe dit bij Sandy Bridge in z'n werk gaat. Vanuit de decoder gaan de instructies niet alleen naar de wachtrij, maar ook naar de MicroOp Cache. Deze cache staat via de branch predictor - het onderdeel dat ondermeer voorspelt welk codepad binnen IF-THEN-ELSE constructies vermoedelijk in de toekomst moet worden genomen - ook weer in verbinding met de instructie cache. Mocht er een instructie binnenkomen die recent al eens is gedecodeerd, hoeft dit niet opnieuw te gebeuren en kan deze direct worden doorgestuurd naar de MicroOp wachtrij. In de cache passen zo'n 1500 gedecodeerde MicroOps.
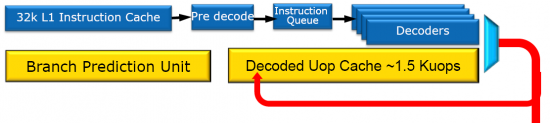
Deze MicroOp cache biedt een aantal voordelen. Allereerst wordt de wachttijd (latency) voordat een instructie daadwerkelijk kan worden uitgevoerd in potentie flink verkort. Lees: betere prestaties. Een ander voorbeeld is dat de instructie decoders geregeld uitgeschakeld kunnen worden. Lees: lager stroomverbruik.
In de tweede afbeelding is ook de branch prediction unit geel gemaakt. Dat heeft Intel gedaan om aan te geven dat ook die verder verbeterd is. Hoewel de branch predictor bij alle nieuwe processorarchitecturen van de afgelopen paar jaar een onderdeel is waar flink aan is gesleuteld, blijft het de moeite waard om de werking ervan te verbeteren. Een verkeerde keuze betekent immers dat de processor heel veel werk voor niets aan het doen is en dus een flinke klap voor de prestaties. Intel wil niet precies aangeven in welk percentage van de voorspellingen de juiste keuze wordt voorspeld, maar uit gesprekken blijkt dat dit inmiddels ver boven de 95% is.
3 besproken producten
| Vergelijk | Product | Prijs | |
|---|---|---|---|

|
Intel Core i5 2300
|
Niet verkrijgbaar | |

|
Intel Core i5 2500K
|
Niet verkrijgbaar | |

|
Intel Core i7 2600K
|
Niet verkrijgbaar |







